
Introducing BastionAI, an Open-Source Privacy-Friendly AI Training Framework in Rust
Discover BastionAI, a Rust project for Confidential deep learning training. BastionAI leverages Confidential Computing and Differential Privacy to make AI training between multiple parties more privacy-friendly
We are pleased to announce that we have released the alpha version of BastionAI, a Rust framework for Confidential deep-learning training! BastionAI leverages Confidential Computing and Differential Privacy to make AI training between multiple parties more privacy-friendly. Please have a look at our GitHub (https://github.com/mithril-security/bastionai) to find out more!
Context
Today, most AI tools offer no privacy by design mechanisms, so when data is shared with third parties to train an AI model, data is often exposed in clear to the operator in charge of the training. This means that in regular centralized approaches if we allow data to move to a central node, data is quite exposed to that party, and if it is in the Cloud, to the Cloud provider as well.
Techniques such as Federated Learning (FL) have emerged to reduce this exposition to train models on multiple datasets.
To see how it works, imagine we have two hospitals wanting to train a model to analyze medical documents to automate admin tasks, and a startup providing the AI and expertise to develop the AI system.
The core idea of FL is that data will not move, but the model will, and each participant will have to train the model locally.
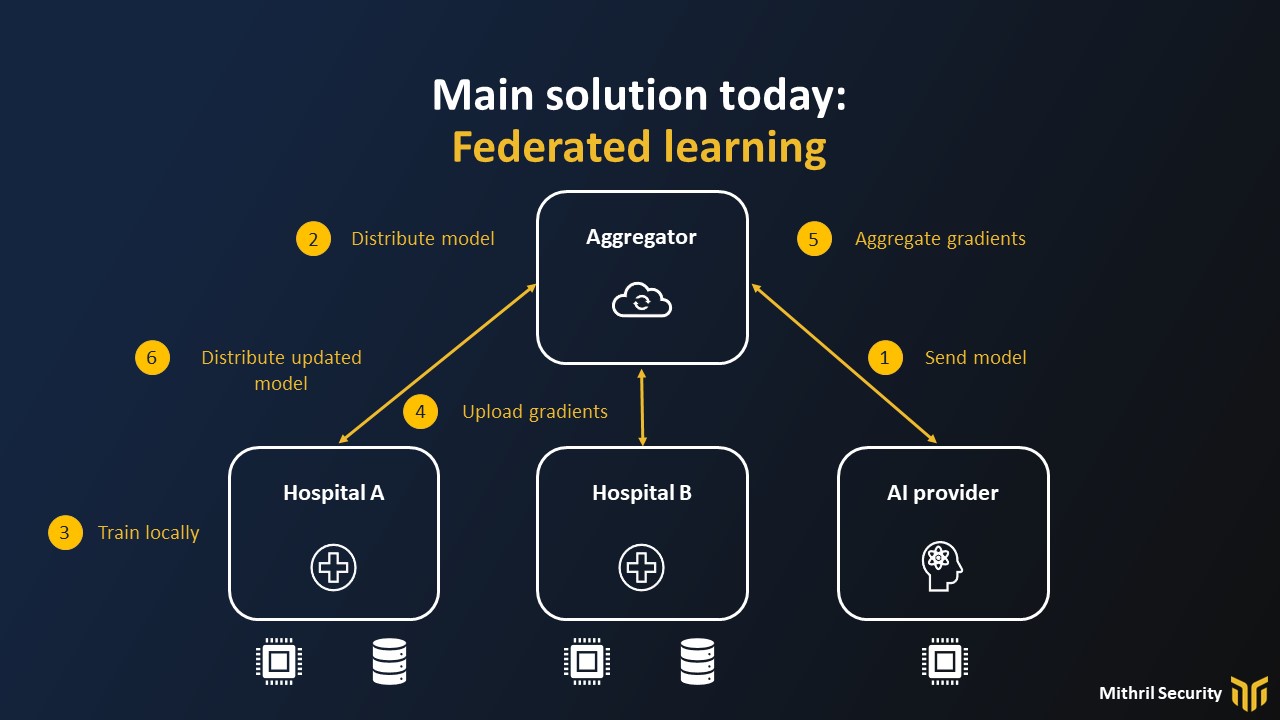
In the case of a central aggregator with FL, the workflow is:
- The AI provider sends the model to the aggregator
- The aggregator dispatches the model to each hospital
- Each hospital trains locally on their dataset
- Each hospital uploads their gradients
- The gradients are averaged to update the model
- The updated model is dispatched
Steps 2 to 6 are repeated until convergence.
Three issues emerge from FL:
- Deployment: Each hospital needs the hardware and software stack to train the AI model. This can be complicated for any company to keep up to date on both of these parts, especially with the latest huge AI models. There cannot be FL as a Service because we must deploy complex infrastructure on each participant premise.
- Scalability: There are huge communication costs, as gradients have to be uploaded to the aggregator and dispatched after aggregation. While methods exist to communicate less, it is still a major bottleneck, especially when you have huge models requiring huge gradients.
- Security and privacy: Gradients and models are usually in clear, but this could leak information about original data. The aggregator for instance can reconstruct information about the participant data set. In addition, it’s hard to verify the integrity of the data and computation of each node, which can lead for instance to poisoning.
Differential privacy can be applied to make the gradients leak less information, but in a decentralized setup, the amount of noise that needs to be injected is huge and disturbs
Just with the two first issues, we believe Federated Learning is not necessarily fit to answer the current needs for multi-party training due to the complexity of deployment and massive overhead. That is why we have built BastionAI, a frictionless privacy-friendly deep learning framework.
Objectives
The goal of BastionAI is to provide a deep learning framework to enable data scientists to train models on multiple parties’ data, with security and privacy.
There are three key properties we want to achieve:
- Speed: low computational time and low communication time.
- Security: data and models should be protected, even when shared with untrusted parties.
- Frictionless experience: the framework should be easy to use by data owners and scientists, and easy to deploy.
Design
To answer all these requirements, we have decided to use a centralized approach for performance and ease of deployment, but with secure enclaves to ensure security and privacy. Let’s have a brief look at Confidential Computing with secure enclaves.
Confidential Computing
Confidential Computing is the use of hardware-based Trusted Execution Environments (TEEs), also called secure enclaves. Those enclaves enable data owners to offload the processing of sensitive information to untrusted third parties, thanks to enclave memory isolation or encryption. We can see it illustrated below with an example of what happens with/without secure enclaves for speech analysis in the Cloud.
In addition to providing data-in-use protection, secure enclaves have a mechanism called remote attestation, where a non-forgeable cryptographic proof can be provided to make sure you are talking to a secure enclave with the right security properties and code. This is great because it means, with secure enclaves, only a code you know and trust will be used on your data!
You can find out more about secure enclaves in our articles Confidential Computing explained, or during our Zero Trust webinar.
So far, only CPUs like Intel Xeons or AMD EPYC were able to provide secure enclaves, but Nvidia announced this year that the coming H100 GPU will have secure enclave capability, which will change the game!
Fortified learning
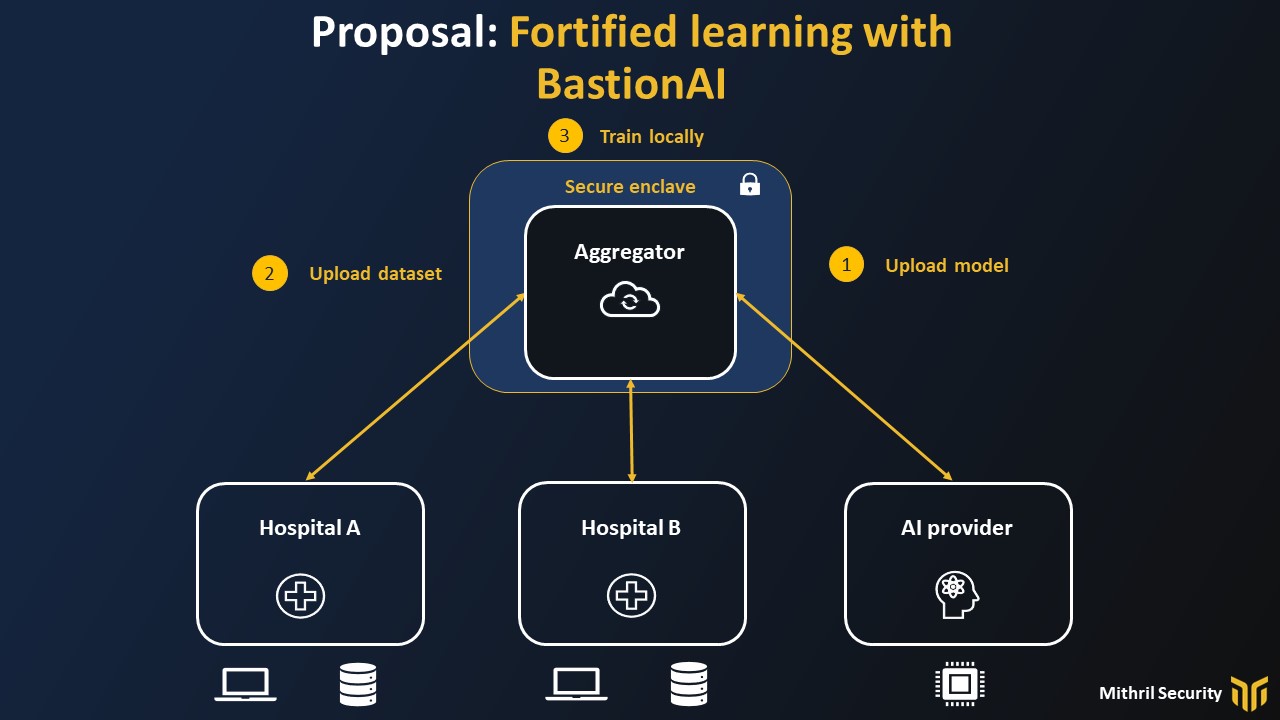
To answer the three obstacles of Federated learning, we propose an alternative, Fortified learning, which will concentrate computations inside a central node, but inside a secure enclave.
Now, most of the workload can be offloaded to a remote secure enclave which answers the different issues:
- Deployment: Each participating node, for instance, the hospital, only needs to have a lightweight Python client to perform remote attestation to make sure they are talking to a secure enclave. This means we no longer need to deploy and maintain complex hardware and software at each participating site, and we can have “Confidential training as a Service” now, which was not possible before.
- Scalability: Because computations remain in a closed loop inside the enclave or cluster of enclaves, communication costs are immensely reduced compared to traditional Federated learning.
- Security and privacy: Secure enclaves isolation and encryption of memory ensure that the models and data of each participant are not exposed to any third party. In addition, with remote attestation we can have the integrity of data and processing, to make sure only people who know will put the correct data and not deviate from the protocol.
Implementation
Overview
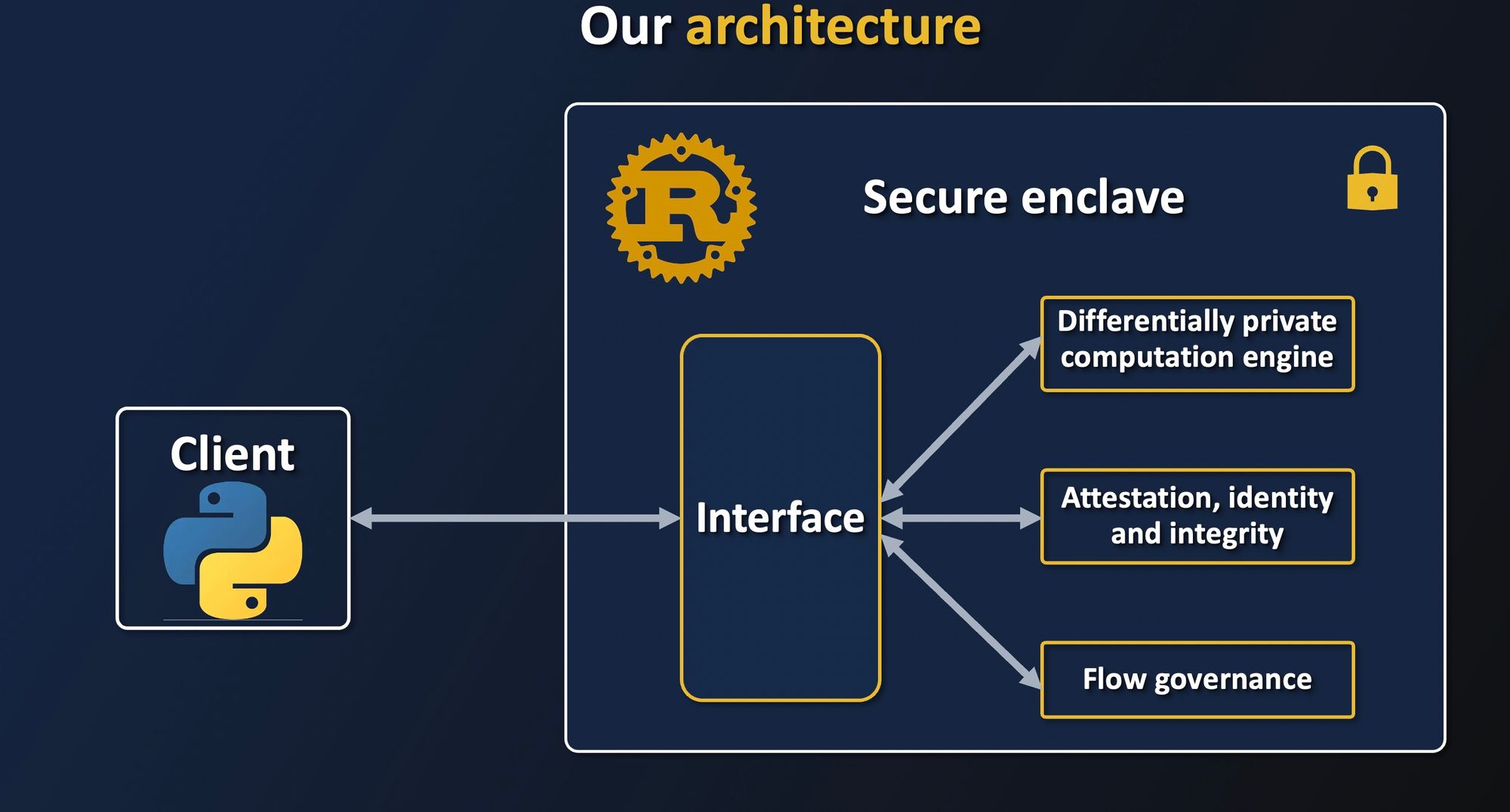
The project is structured in two parts:
- A lightweight Python client, which enables data owners and data scientists to verify the security properties of a remote enclave that will perform the computation.
- A Rust server, which will be in charge of protecting data with encryption and attestation, and performing computation securely with Differential Privacy.
A - Targeted hardware: AMD SEV SNP with Nvidia secure enclave
While Nvidia secures GPUs with the coming H100 are not available, we plan to support them as soon as possible. Because secure GPUs require a secure CPU to work, the H100 will be paired with a Confidential VM, today provided by the AMD SEV SNP feature.
We will also support the upcoming Intel TDX technology once available.
B - Rust
We wanted a low-level solution to best be able to leverage hardware features of secure enclaves, such as management of enclave-specific keys, and for performance.
Naturally, Rust has emerged as the natural solution as it answers our 4 main criteria for a secure AI solution in the enclave:
- Memory safety, which helps secure the code inside the enclave that has to manipulate sensitive data.
- Low-level granularity, to help handle close-to-the-metal features of secure enclaves, such as attestation and sealing mechanisms, which are important features for some complex key management scenarios.
- Performance, which is key for an AI deployment at scale.
- Modern tooling, which facilitates collaboration with crates and cargo to manage dependency and packages more easily and cleanly.
C - PyTorch + Opacus
To provide a smooth experience for data scientists, we have decided to use PyTorch as our computational backend for BastionAI.
We have leveraged the tch-rs project to have hooks to interface with PyTorch’s backend, in order to train AI models provided by users. Thanks to PyTorch compatibility, users can natively send Torchscript models and datasets to the enclave.
Finally, using Opacus enables us to transparently provide Differential Privacy (DP). DP is key to making sure that even if we share the model with someone else, the model will not leak information about the training data used.
Experiments
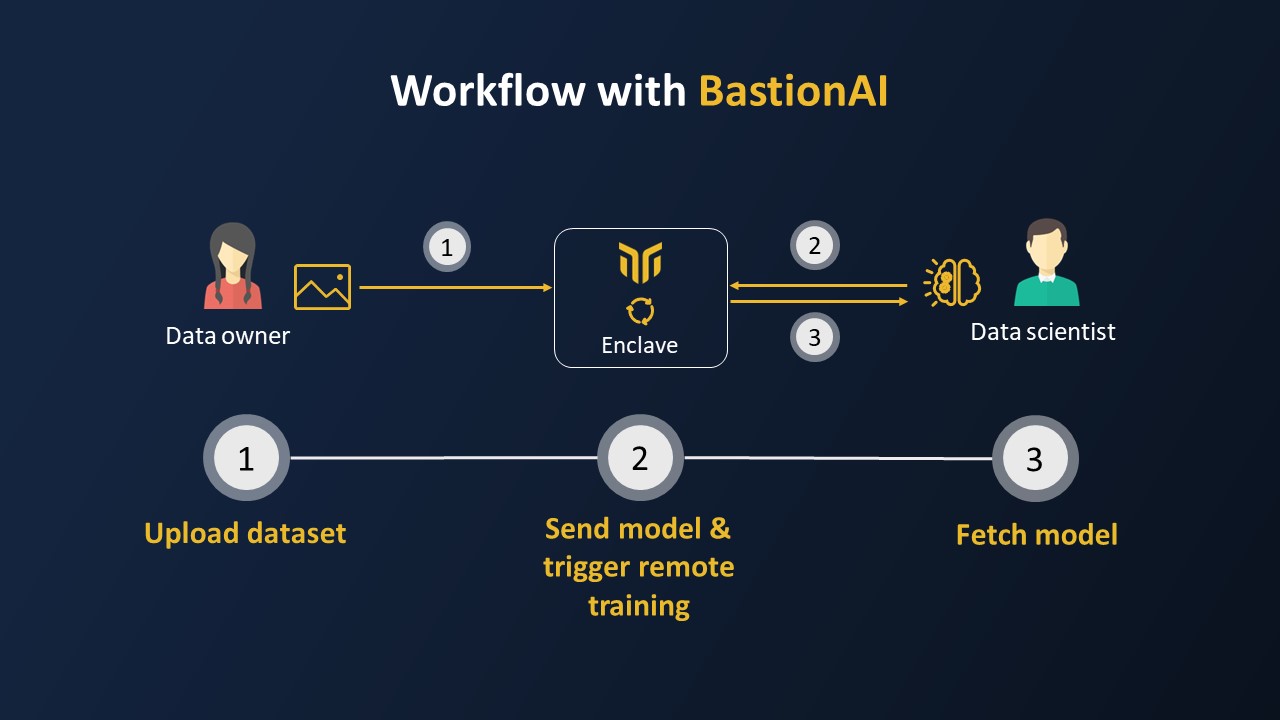
The workflow to use BastionAI is pretty straightforward:
- The data owner will prepare the dataset locally, and have it available in a PyTorch
DataSet, before uploading it to a secure enclave after remote attestation. At upload time, the data owner can define who is authorized to train a model on it, and how much Differential Privacy budget is allowed. - The data scientist prepares the model locally and has it available in a PyTorch
nn.Module. Then they will ask the enclave to provide a list of available datasets, pull a reference to the remote dataset, ask the model to be applied to this dataset, and once training is over, pull the weights.
We provide an example notebook, where we show how to finetune a DistilBERT model on a private dataset, SMS spam classification, with Differential Privacy inside a secure enclave.
We have initial benchmarks to see the performance gains of Fortified learning vs Federated learning.
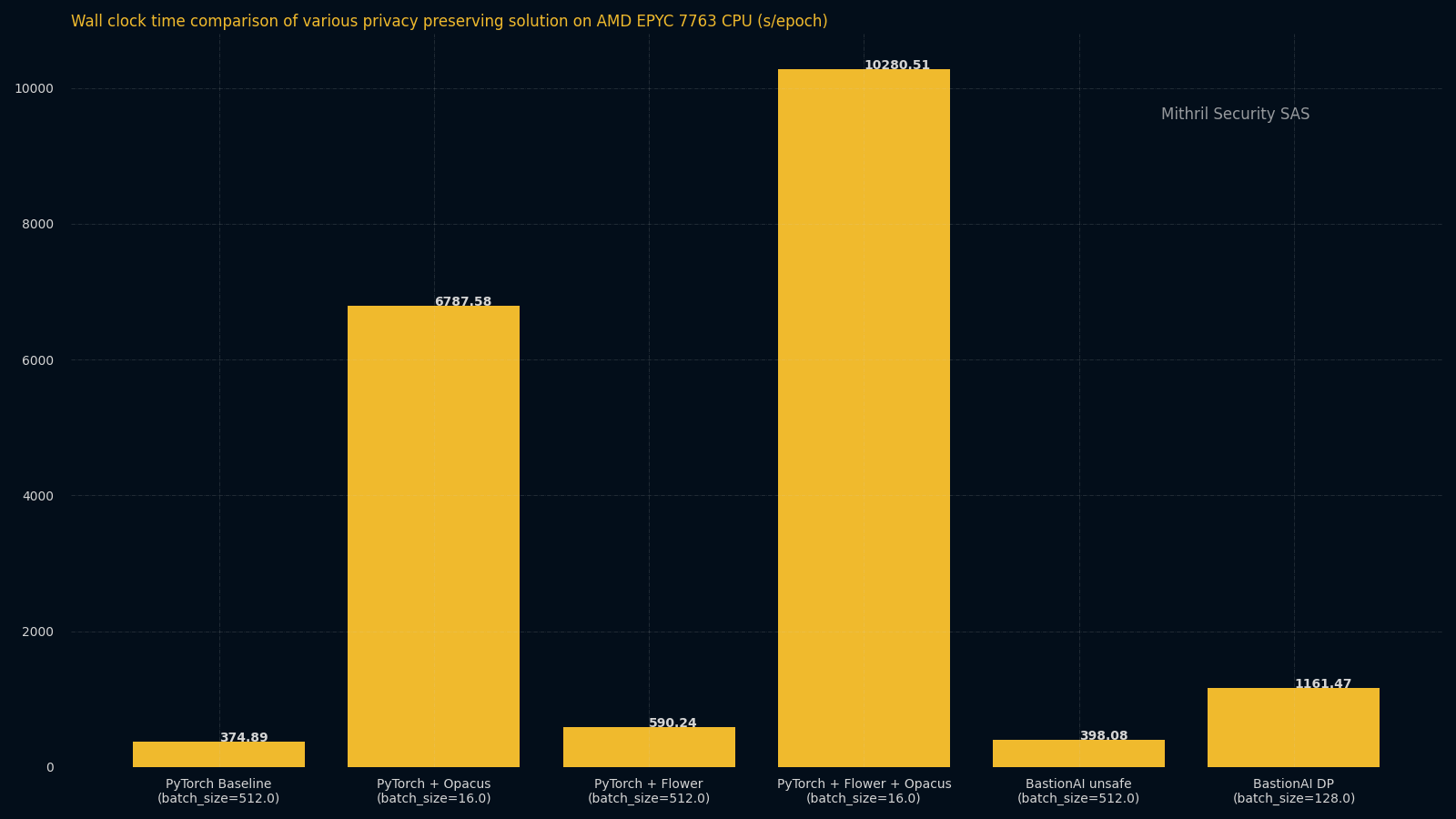
Initial benchmarks are done using a Confidential VM approach with AMD SEV SNP. We will provide benchmarks using the upcoming Nvidia H100 secure enclaves once available.
Here we compare the time to do one epoch of an EfficientNet between:
- PyTorch alone
- PyTorch with Opacus for DP
- PyTorch with Flower for FL on 2 nodes
- PyTorch with Flower and Opacus on 2 nodes
- BastionAI without an enclave
- BastionAI without an enclave with DP
- BastionAI with an enclave
- BastionAI with an enclave with DP
We can observe usually a 2-3X increase with our solution between confidential training with FL vs BastionAI!
Benchmarking scripts will be made open-source soon.
Conclusion
BastionAI is a novel framework that presents promising properties to democratize confidential training of deep learning models. Its design, made for speed, security, and ease of use, could potentially help unlock the deployment and bottleneck issues of traditional Federated learning frameworks.
We welcome contributions to help us grow our confidential AI training framework. So if you are interested, come drop a star and contribute on GitHub, and reach out to us on our Discord!


{kind=link}