
Data Science: The Short Guide to Privacy Technologies
If you’re wondering what the benefits and weaknesses of differential privacy, confidential computing, federated learning, etc are, and how they can be combined to improve artificial intelligence and data privacy, you’ve come to the right place.
Differential Privacy. Confidential Computing. Federated learning. Homomorphic Encryption. Secure multi-party computation… Those terms have been going around in data, cyber, and privacy circles for a while now! Many privacy solutions have started using them and collectively refer to them as privacy-enhancing technologies (or PETs, as we’ll call them for the rest of this article). But what are their specificities? What are their benefits and weaknesses today?
PETs are a collection of solutions to ensure privacy so we can improve our ability to research, collaborate, and reduce bias in data analysis. On the industry’s side, they could allow collaborations with sensitive data that were impossible until now and lead to better diagnosis of cancer in hospitals or better fraud detection in banks. On the consumer side, they would protect from data leaks and their consequences, like identity theft and discrimination.
Those technologies’ possibilities are very promising, but it can be hard to navigate how and why without clear material on their many particularities. Except, we’re in luck! An article, Beyond Privacy Trade-offs with Structured Transparency, shines a light on this topic to clarify how PETs can be used in combination to improve privacy all around and what each of them brings to the big picture.
Key Takeaways:
1. PETs offer various benefits, such as enabling collaborations with sensitive data, enhancing diagnosis in healthcare and fraud detection in finance, and protecting individuals from data leaks, identity theft, and discrimination.
2. Combining PETs has the potential to enhance overall privacy, but challenges remain in terms of implementation, infrastructure compatibility, and cost.
The 5 Problems of Privacy
To ensure privacy during data analysis, five problems need to be resolved according to the paper: input privacy, output privacy, input verification, output verification, and flow governance.
- Input privacy is the ability to process data that is hidden from you. It should also allow others to use your information without revealing it to them. An applied example of this would be letters: mail services can process them without knowing their content because it is hidden by the envelope.
- Output privacy is when you can’t infer the input of a data flow from its output. Continuing the letter analogy, it shouldn’t be possible to figure out who wrote an anonymous letter by analyzing the writing style. For example, it is possible to reverse engineer pseudonymized databases, which is a method that replaces personally identifiable information fields with one or more artificial identifiers, or pseudonyms. This is one of the reasons de-identification methods aren’t considered true anonymization and privacy experts are looking at PETs.
- Input verification is verifying that the data you receive is from a trusted source. It identifies files, like a signature.
- Output verification is verifying that the output is the expected result from the input and hasn’t been tampered with. It’s the wax seal on an envelope.
- Flow governance is a way to guarantee the integrity of the data flow through hard (mathematical, physical…) limits. Imagine a letter shipped in a safe with a combination lock only the recipient knows. We’ll agree this is not very realistic with a real-life example because flow governance is meant for digital purposes, but it would make sure that no one could open the envelope or tamper with its content. Solving this particular problem would get rid of the need to trust a system, as governance could be implemented by cryptographic limits instead of legal threats against offenders, for example.
How Do PETs Protect Your Data?
Here’s a little chart to map out which PETs solves which problem:
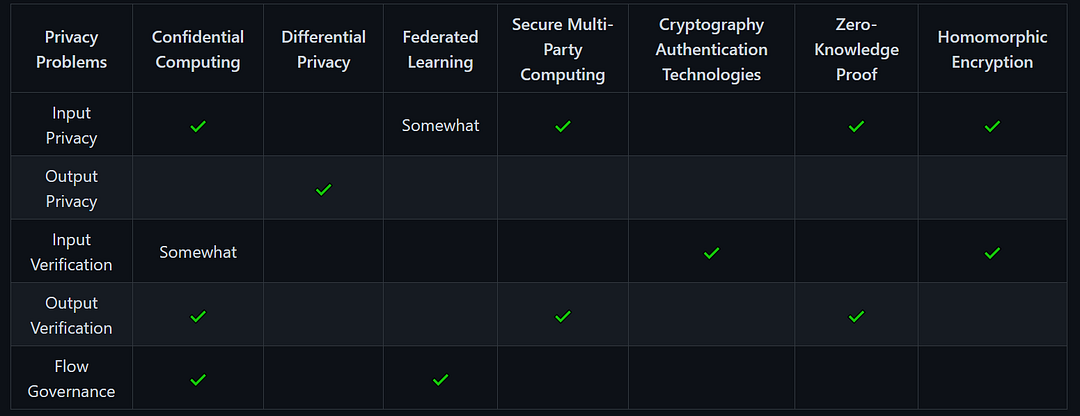
- Confidential Computing
Confidential computing is a security technology that isolates sensitive data in a dedicated space in the core processor. This space also called a Trusted Execution Environment or enclave, is guaranteed to be safe because the hardware is the only instance that can see the data when processing it. No human can interfere.
Confidential computing isn’t only for privacy purposes, but when used with privacy in mind, it can solve many of the 5 privacy problems. Its hardware-based guarantees can be very powerful: they can ensure input privacy, for example because everything (the data, an AI model, the codebase…) is processed in opaque hardware space. Confidential computing can also handle input verification because it uses cryptography (we wrote somewhat because this is not really a feature of confidential computing but more a byproduct of using cryptography). Output verification is handled by the attestation system, which can authenticate that the result is what was expected. Flow governance could be determined by both cryptography and hardware-based guarantees.
- Differential Privacy
Differential Privacy is a mathematical framework that disconnects input from output using probabilities. The way it works is quite complex, but if we simplify it, it uses noise and other mathematical tools to protect the privacy of individuals in datasets.
It’s great because it prevents singular elements from ever leaking — if it’s correctly implemented. Differential privacy was designed for output privacy, as its function is to prevent inferring the input from the output.
- Federated Learning
To explain Federated learning, let’s take an example: many hospitals want to train a model that can better diagnose cancer. They all need to use their data, but they also don’t want to move the data out of their server and centralize it somewhere else. This would be a privacy and security nightmare requiring absolute trust from all participants (at least the hospitals, the patients, and the third parties providing the AI model). Researchers came up with another idea: instead of moving the data, what if the hospitals moved the AI model so it could learn locally?
This is great in theory, but this creates weaknesses: for example, input privacy can’t be fully guaranteed. A model could overlearn (or overfit) from one of the hospital’s datasets. Then, targeted by an input inference attack, data could be accidentally leaked whether the model is in production or deployed. Flow governance, however, is a strength of Federated learning as it distributes instead of centralizing data processing.
- Secure Multi-Party Computing
Secure multi-party computing is a collection of methods that exchange messages between multiple parties in a way that none of them can learn anything from the others — except the final result.
There are multiple variants and multiple protocols, but the concept stays the same by mathematically covering the tracks to protect input privacy. It also handles output verification because no machine can influence or modify the protocol — the result can’t be tampered with (unless the input itself is false, but that is part of the input verification, and secure multi-party computing doesn’t handle that by default).
- Cryptography Authentication Technologies
Cryptography allows to have a signature that allows data authentication — and, by default, input verification.
- Zero-knowledge Proofs
Zero-knowledge proofs are, as their name indicates, cryptographic proofs that can be trusted without knowing their input.
They are often built interactively: the person trying to prove they have the knowledge gets sent challenges that can only be answered if you have the knowledge but won’t give away the knowledge. In general, multiple challenges are required for zero-knowledge proof. This guarantees input privacy as the input is never revealed, as well as output verification since the answer to the challenge is already known and can’t be falsified.
- Homomorphic Encryption
Homomorphic encryption makes it possible to process encrypted data. This is such a powerful security technology that it is not ready yet for everyday use. It requires an incredible amount of computational power and its circuit-based approach makes it hard to use it for complex requests.
Its applications in privacy could, however, be quite interesting as it would ensure input privacy and input verification thanks to encryption.
Combining PETs for Privacy
Combining PETs seems like the obvious solution to improve privacy — but there are still many obstacles to widespread adoption. Mostly, tools still need to be built to use those complex technologies with today’s infrastructures and at a realistic cost. Our open-source privacy frameworks for data science collaboration, BastionLab, and BlindAI are among the solutions that are being developed to manage these goals. They use Confidential Computing mainly, which is by far the PET solving most privacy challenges.
When the ecosystem becomes mature, says the research paper, it could improve data flow for open research, enable large-scale collaboration for social good, and ensure verification and bias. It is, however, important to keep in mind one key limitation: enforcing more precise data flows doesn’t guarantee that they are ethically designed or socially beneficial.
Reference
Beyond Privacy Trade-offs with Structured Transparency, Andrew Trask, Emma Bluemke, Ben Garfinkel, Claudia Ghezzou Cuervas-Mons, Allan Dafoe (2020), https://arxiv.org/abs/2012.08347


{kind=link}