
Insights of Porting Hugging Face Rust Tokenizers to WASM
Learn how Rust can be used to port server side logic, like Hugging Face Tokenizers, to the client for security and performance using WASM.
We will see how we can use WASM to port the Hugging Face Rust Tokenizers server library to create a client-side JS SDK for web browsers.
Porting server logic to the client can be done for performance and/or security reasons. Rust is an excellent language for that purpose as it can easily be compiled to WASM, which enables us to "easily" allow clients, from web browsers to Android and iOS, to execute server-side logic.
In a Nutshell:
Porting server-side logic to the client using WASM offers performance optimization and data security benefits, making it an effective approach for deploying AI models in web browsers.
Use case
What are Tokenizers?
The Rust Tokenizers project is a preprocessing library by Hugging Face for Natural Language Processing AI models. It is an implementation of the most widely used tokenizers, for instance, Byte Level BPE for GPT models or WordPiece for BERT models, with an emphasis on improving performance and versatility.
Tokenizing is the act of splitting a sentence into small pieces, and then converting them to the corresponding entries in a vocabulary for a neural network to ingest, as neural networks do not operate on raw text.
For instance, we can see how a BERT tokenizer splits a sentence and associates each token to an index:
>>> from transformers import BertTokenizer
>>> sentence = "I have a new GPU!"
>>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
>>> print(tokenizer.tokenize(sentence))
['i', 'have', 'a', 'new', 'gp', '##u', '!']
>>> print(tokenizer(sentence)["input_ids"])
[101, 1045, 2031, 1037, 2047, 14246, 2226, 999, 102]Why porting to WASM?
Now that we have seen what Tokenizers do, let’s see why we would want to port it to the client side.
Performance
When you want to deploy a model at scale, it is common to export your Pytorch/Tensorflow model to ONNX for deployment using a specialized framework like Triton. Those frameworks will perform a lot of optimization to get the best speed, but they need the model to only use a specific set of operators, matrix multiply, ReLU, CNN, etc.
However tokenization is an operator outside of the scope of the regular operators, and therefore it might not be easy to package your preprocessing and inference in a single bundle that can be taken by inference frameworks.
This means you might need to add preprocessing separately, for instance using Python scripts, which can cause an overhead. If you are using another language for most of your app, for instance, Java, switching to Python to resort to Tokenizers will also add a bottleneck.
Therefore doing the tokenization on the client side helps have a more homogenous backend, and can lead to performance improvement.
Security
In addition, using Tokenizers can expose data in the world of secure enclaves. At Mithril Security, we have developed BlindAI, an open-source AI deployment solution for confidential inference.
By using BlindAI, data owners can benefit from remotely hosted AI solutions, for instance in the Cloud, without exposing their data in clear to the AI provider or the Cloud provider, thanks to the use of secure enclaves.
For instance, if we want to deploy a Speech to text model in the Cloud, we see in the above scheme how regular solutions could expose recordings to the Cloud provider or the startup, and how BlindAI can provide a secure environment making data always protected.
The problem we face is that even if we analyze confidential data inside a secure enclave, some operations performed inside the enclave can leak information. Side-channel attacks use information visible to the outside such as timing or memory access of enclaves to deduce information about data handled inside the enclave.
While most operators we support for inference, like ONNX operators, can be made side-channel resistant, tokenizing involves a lot of operations like lookups or branching that can expose data, even when used in a secure enclave.
Therefore, porting the tokenization step to the client solves this problem, as we no longer expose data to potential side channels that happen on the server side. This greatly improves the privacy of users who would like to resort to remote NLP models to analyze their texts.
Porting to WASM
Now that we have seen why porting the server-side Rust Tokenizers library to the client is relevant, let’s see how to actually do it.
The Rust 🦀 and WebAssembly 🕸 book is an excellent resource to learn how to port Rust to WASM.
The workflow to port a Rust crate to WASM is:
- Make the Rust codebase WASM compatible
- Provide an interface for JS code
- Compile it into a wasm module
- Use it from JS
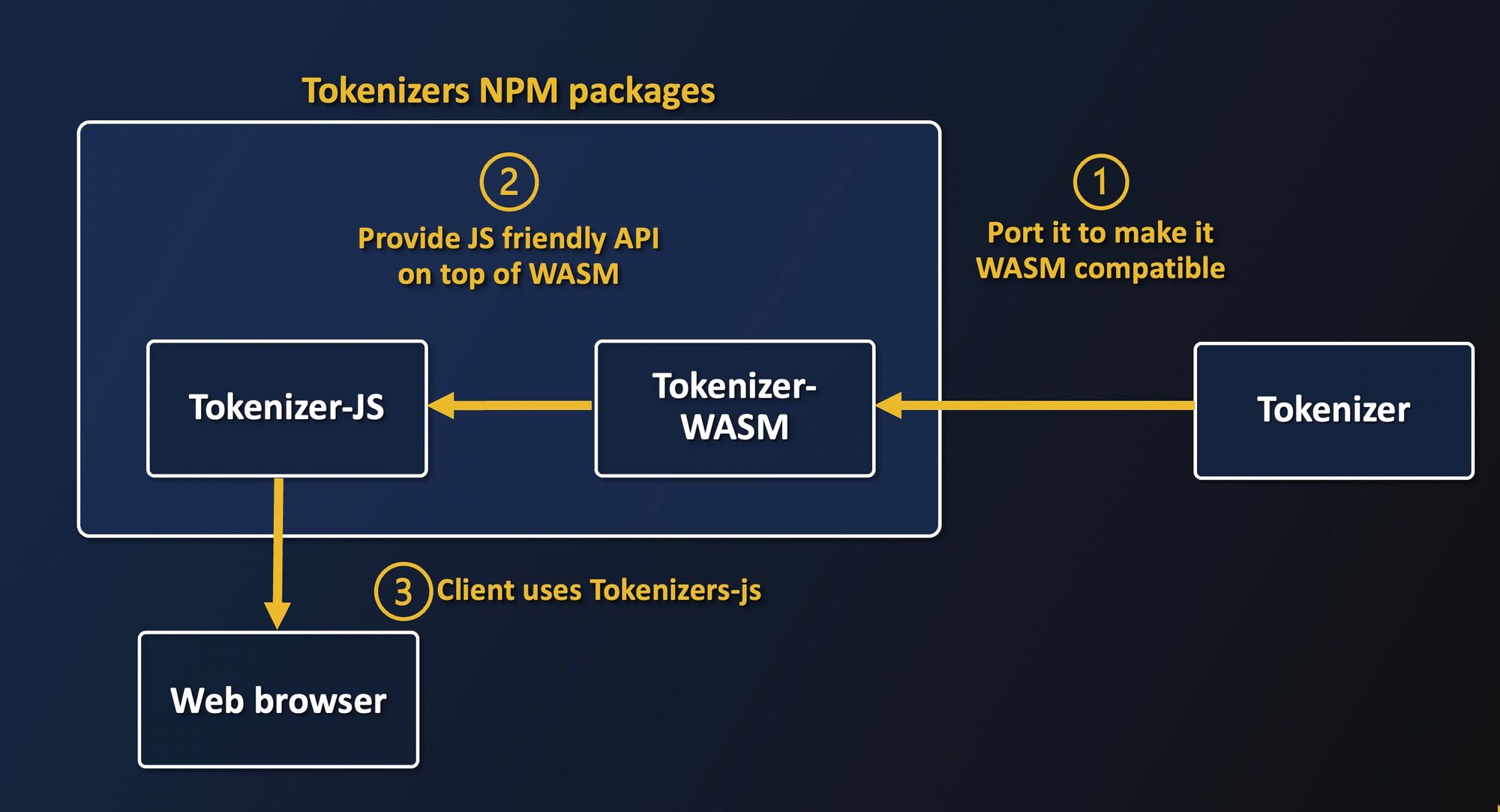
The above figure shows the global process: we first make Tokenizers WASM-compatible, compile it and provide an abstraction layer to have a native JS experience, and package everything for browser consumption.
1 - Make the codebase WASM compatible
The first step is to make the Tokenizers codebase WASM-compatible. Most Rust code is compatible by default, but there are some exceptions and pitfalls. Here is what we had to change in the Tokenizers codebase in order to make it WASM-compatible:
- Some features use the filesystem, so we disabled them because WASM can’t access the file system.
- There is a C dependency for regex, so we used another regex library written in Rust instead.
This WASM-compatible version of Tokenizers is available through the unstable_wasm feature. It has been upstreamed on the Tokenizers repository and is now usable, though not yet thoroughly tested.
2 - Provide an interface for JS code
Once the Rust code is WASM-compatible, you could theoretically compile it into a WASM module. However, by default, you wouldn’t be able to call any of the originally available methods.
Indeed, wasm_bindgen needs to generate the appropriate Rust code to translate from the method's type signature to one that JavaScript can interface with. As an example, let’s imagine you have a Rust crate in which the sources look like this:
pub fn hello_world {
"Hello World"
}To expose the hello_world function to JS code, you would need to transform it like so:
extern crate wasm_bindgen;
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub fn hello_world {
"Hello World"
}Also, we couldn’t directly use wasm_bindgen in the original codebase because some of Rust’s features like traits, generics, and lifetime parameters are not supported wasm_bindgen yet. Thus we needed to consume the problematic classes and methods into a wasm_bindgen friendly Rust code.
For instance, this function is not exposable:
pub fn add<T>(a: T, b: T) -> T {
a + b
}Because it expects a generic as a parameter.
But you can consume it like this:
#[wasm_bindgen]
pub fn js_add(a: f64, b: f64) -> f64 {
add(a, b)
}Since float is the only number type in JavaScript, the loss of the genericity here doesn’t matter.
The Tokenizers library bindings for WASM can be found here: tokenizers-wasm.
3 - Compile it in a WASM and wrap it
Once this is all done, we just need it to compile our adapted Tokenizers package to WASM.
We first need to install wasm-pack, then use wasm-pack build to create a WASM package. Once this is done, the Rust crate is now successfully ported to WASM, and we can push it to npm with wasm-pack publish. You won't have to do it, as we did it, and this package can be found here on npm: tokenizers-wasm.
However, a Rust-generated WASM package can only use the programming language features common to both JavaScript and Rust. This means that it is not possible to expose a complex library like Tokenizers since we are lacking essential features, such as the ability to pull a pretrained tokenizer model from Hugging Face Hub.
To circumvent this issue, we created a JavaScript wrapper called tokenizer-js whose aim is to expose a more Tokenizers-like API. It consumes the methods of tokenizers-wasm and reorganizes them using idiomatic and object-oriented JavaScript.
For instance, the model pulling from the Hugging Face Hub is not enabled with the unstable_wasm feature due to its use of the filesystem or network. So we provided a JS abstraction layer to use it:
static from_pretrained(name) {
Return
fetch("https://huggingface.co/${name}/resolve/main/tokenizer.json")
.then(response => response.text())
.then(json => new Tokenizer(json));
}So in the end, the JS package that correctly exposes the Tokenizers library can be found here on npm: huggingface-tokenizers-binding.
The full package code is available here: https://github.com/mithril-security/tokenizers-wasm
4 - Use it from JS
Now that we have a working JS version, let’s use it on the client side.
For this, we will dive into a very simple example, which pulls a pre-trained tokenizer from the Huggingface hub and encodes an input with it, all in JavaScript that can be executed on your browser.
You will need to install nodejs and npm via your package manager. This is because we want to serve a page that is running Tokenizers inside the browser.
First, run this to create a template webpack app:
npm init wasm-app tokenizers-appThis will generate the necessary files to make Rust-generated wasm modules work with JavaScript. If you have never used webpack before, it’s a JavaScript module bundler that completely supports WASM.
Once this is done, go into the directory and paste this code in place of the index.js file:
import { Tokenizer } from "huggingface-tokenizers-bindings";
async function main() {
let tokenizer = await Tokenizer.from_pretrained("gpt2");
let encoding = tokenizer.encode("I love AI and privacy", false);
console.log(encoding.input_ids);
}
main();As you can see the API is quite similar to the original Tokenizers library.
Finally to run it, execute:
npm install --save huggingface-tokenizers-bindings
npm run start
Open the given link in your browser, here it would http://localhost:8080/, open the console and you should see the following outputs:
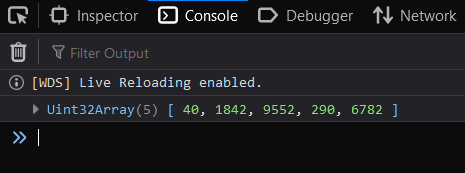
Those results are the same that you will get by running the original Python library:
>>> from transformers import AutoTokenizer
>>> tokenizer = AutoTokenizer.from_pretrained("gpt2")
>>> encoding = tokenizer("I love AI and privacy")
>>> print(encoding.input_ids)
[40, 1842, 9552, 290, 6782]Et voila! We can see that our porting of Tokenizers provides the same results 🤗
Conclusion
We have seen in this example how we can leverage Rust to port server-side logic to the client using WASM as an intermediate.
This helps answer security issues when we need to have some complex data manipulation initially written for the server, and sometimes for performance improvement as well to avoid inserting Python scripts in the backend.
We hope you liked our first Rust article! If you are interested in privacy and AI do not hesitate to drop a star on our GitHub and chat with us on our Discord!


{kind=link}