
Technical collaboration with the Future of Life Institute: developing hardware-backed AI governance tools
The article unveils AIGovTool, a collaboration between the Future of Life Institute and Mithril, employing Intel SGX enclaves for secure AI deployment. It addresses concerns of misuse by enforcing governance policies, ensuring protected model weights, and controlled consumption.
Introduction
Over the past couple of years, we have seen the uptake of the usage of powerful LLMs such as ChatGPT skyrocket. While these groundbreaking models can help us to advance in a wide range of sectors, there are increasing concerns around potential misuse, from cyber threats to massive disinformation campaigns.
This concern is reflected in increased efforts to regulate powerful AI systems, with, for instance, the recent EU AI Act. While AI regulations are a welcome and necessary step to defining desirable properties of a safe AI system, we lack production-ready and technical solutions to enforce those properties in practice.
This is why we have partnered up with the Future of Life Institute to develop technical frameworks to enforce AI governance policies with hardware guarantees. The Future of Life Institute is a pioneering organization whose goal is to reduce the existential risks of AI. It has contributed to fostering AI safety with initiatives such as:
- An Open Letter to pause the training of AI systems more powerful than GPT4
- Recommendations for the UK AI Safety Summit
- Governance Scorecard and Safety Standards Policy
In this article, we will present in detail how we have leveraged hardware-based technology, with Intel SGX enclaves, to deploy AI models with cryptographic guarantees that the model weights are protected and consumption of the model is cryptographically verified and controllable.
This project builds on BlindAI, our open-source and previously audited AI deployment framework, and serves as a proof of concept of the potential of enclaves (confidential and verifiable computing environments) as a means to enforce AI governance policies. While BlindAI is no longer maintained, we continue to leverage enclaves in our core project BlindLlama, which crucially additionally supports the use of GPUs.
Context
AI safety has become a key subject with the recent progress of AI. Debates on the topic have helped outline desirable properties a safe AI should follow, such as provenance (where does the model come from), confidentiality (how to ensure the confidentiality of prompts or of the model weights), or transparency (how to know what model is used on data).
While these discussions have been necessary to define what properties an AI should have, they are not sufficient as there are few technical solutions to actually guarantee that those properties are implemented in production.
For instance, there is no way to guarantee that a good actor who trained a safe AI has deployed the intended safe model, nor is it possible to detect if a malicious actor is serving a harmful model. This is due to the lack of transparency and technical proof that a specific and trustworthy model is indeed loaded in the backend.
Fortunately, modern techniques in cryptography and secure hardware technology provide the building blocks for verifiable systems that can enforce AI governance policies. For example, unfalsifiable cryptographic proof can be created to attest that a model comes from applying a specific code to a specific dataset. This could prevent copyright issues, or prove that a certain amount of training epochs were done, thus limiting the compute used.
We have partnered with the Future of Life Institute, an NGO leading the charge for safety in AI systems, to create AIGovTool, a project to demonstrate how AI governance policies can be enforced with cryptographic guarantees.
In a first phase of the project, we created a proof-of-concept demonstration of confidential inference.
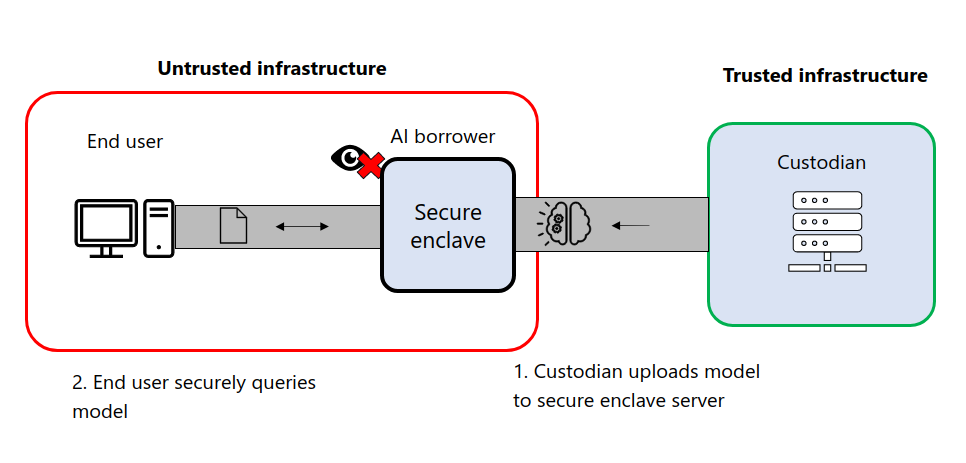
Leasing of confidential and high-value AI model to an untrusted party
The use case targeted by this POC involves two parties:
- an AI custodian with a powerful AI model
- an AI borrower who wants to consume the model on their infrastructure but is not to be trusted with the weights directly
The AI custodian wants technical guarantees that:
- the model weights are not directly accessible to the AI borrower
- trustable telemetry is provided to know how much computing is being done
- a non-removable off-switch button can be used to shut down inference if necessary
Current AI deployment solutions, where the model is shipped on the AI borrower infrastructure, provide no intellectual property (IP) protection. The AI borrower can extract the weights unbeknown to the custodian with relative ease.
Through this collaboration, we have developed a framework for packaging and deploying models in an enclave using Intel secure hardware. This enables the AI custodian to lease a model, deployed on the infrastructure of the AI borrower, while having hardware guarantees the weights are protected and the trustable telemetry for consumption and off-switch will be enforced.
A secure enclave is a hardware-based, highly confidential environment that ensures confidentiality of its data and code integrity. More technical details about secure enclaves, such as hardware requirements, confidentiality, and integrity properties, are provided in the technical deep dive.
Main ideas
To answer the needs of this controlled AI usage, the custodian will ship a hardware enclave (in our case, we use an Intel Xeon 3rd Gen processor), which contains a code with all the right restrictions, and whose properties will be enforced by the secure hardware.
The main job of the secure enclave is to:
- Ping the custodian infrastructure, and prove its identity and security properties, notably proving that the secure enclave has not been tampered with.
- Receive the model, sent by the custodian after cryptographic verification of the enclave, and then serve it.
- Ensure the custodian is always in control. The enclave acts as an AI DRM for the custodian.
Components
AIGovTool is made up of three main components:
End-user client:
The end-user client-server is used by AI consumers to query the model inside the enclave server.
Secure enclave server:
This server is deployed by the AI borrower and enables them to host the custodian’s AI model without having access to the model weights, thanks to the use of secure enclaves.
Custodian server:
This is the server used by the custodian to:
- Securely upload the model to the enclave hosted by the AI borrower
- Follow the consumption of AI models
- Block all future consumption of AI with immediate effect by using an “off-switch”
Demo
A demo can be found here to see our project work in practice. In this demo, we deploy a COVIDNet model on an Intel SGX enclave. We will show two main properties:
- Monitored AI consumption
- AI Off-switch
Monitoring AI consumption
While access control policies could be customized for different use cases, for our POC, we provided the end user with a limited number of queries which can be set by the custodian before shipping the solution.
Before running each inference, the enclave server will check with the custodian server that the user has enough compute budget to inference the model. If the end user exhausts their initial compute budget, they will no longer be able to consume the AI until a further compute budget is unlocked by the custodian.
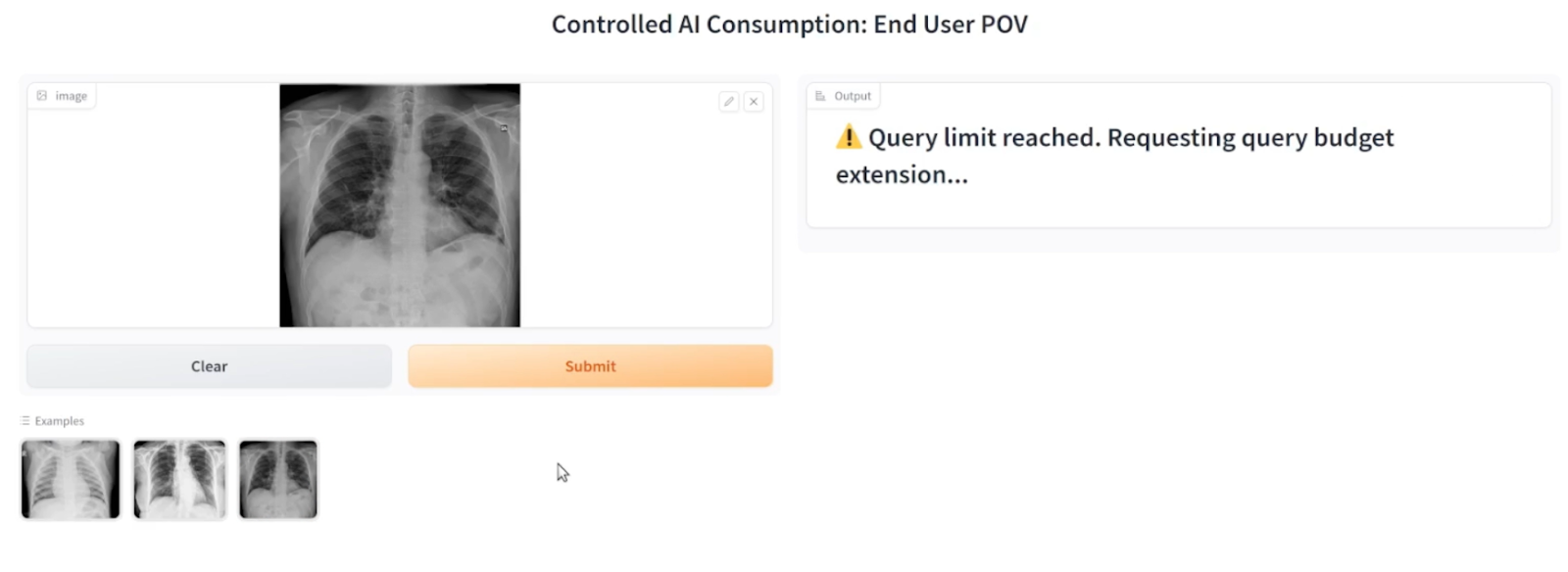
Demo of end-user reaching compute quota
Manual AI off-switch
With the manual AI off-switch, if the custodian shuts down their server, the secure enclave server will no longer approve any end-user requests, thus rendering the AI model useless.
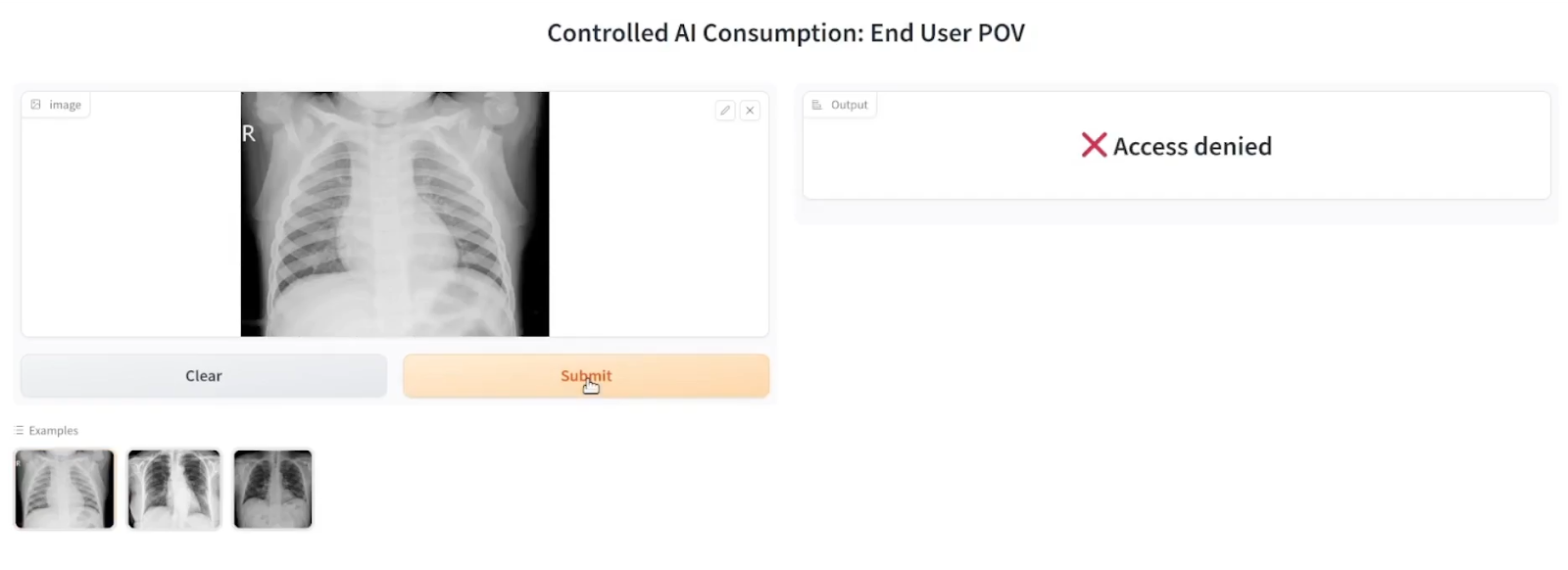
Demo of access denial if custodian shuts down server
Workflow
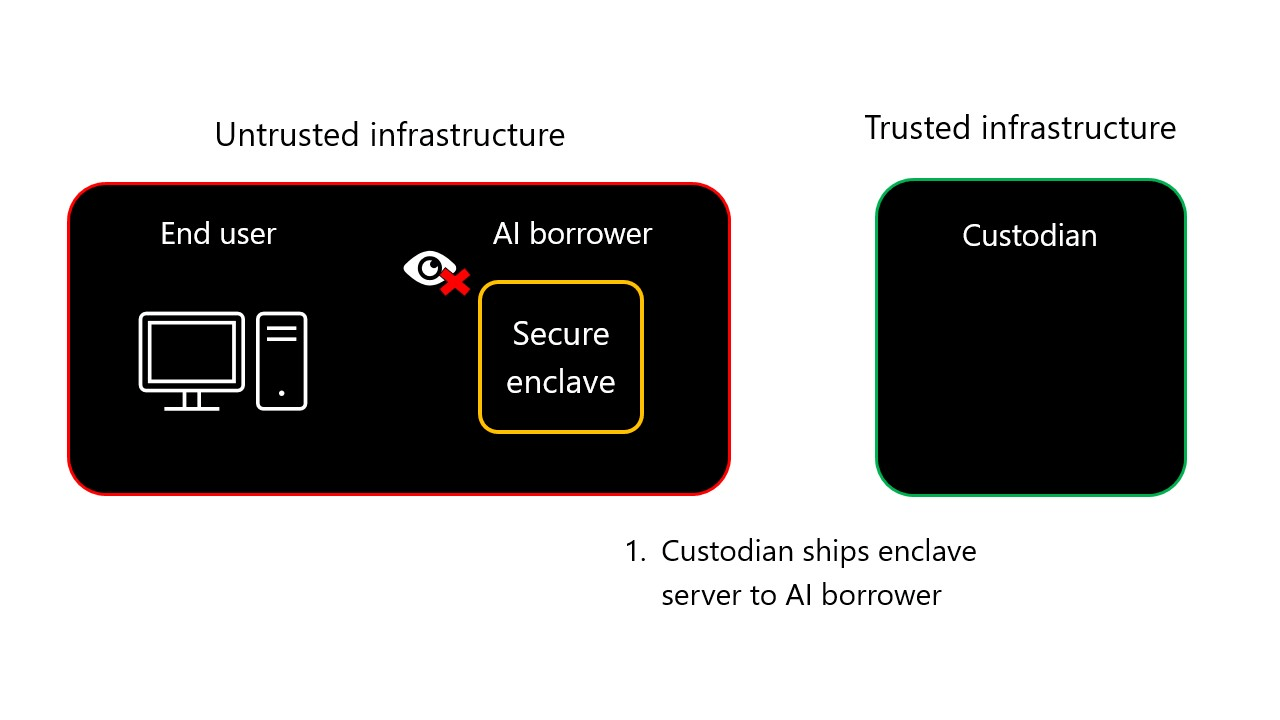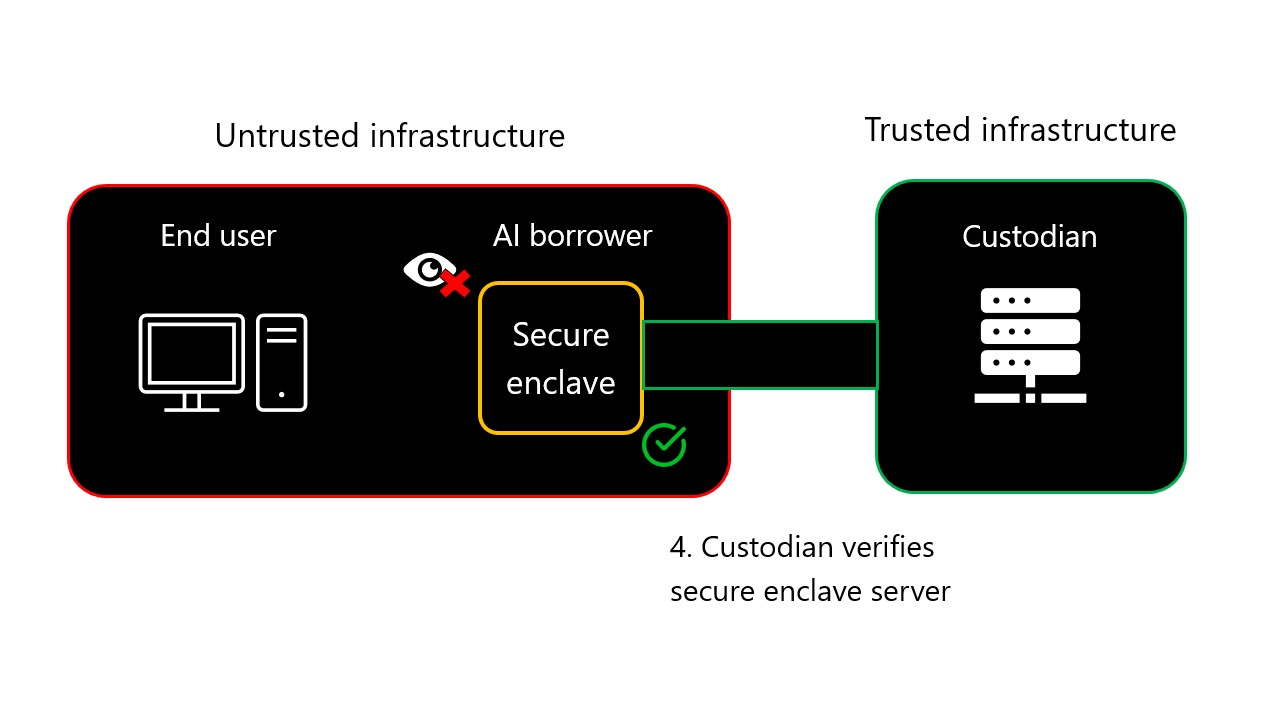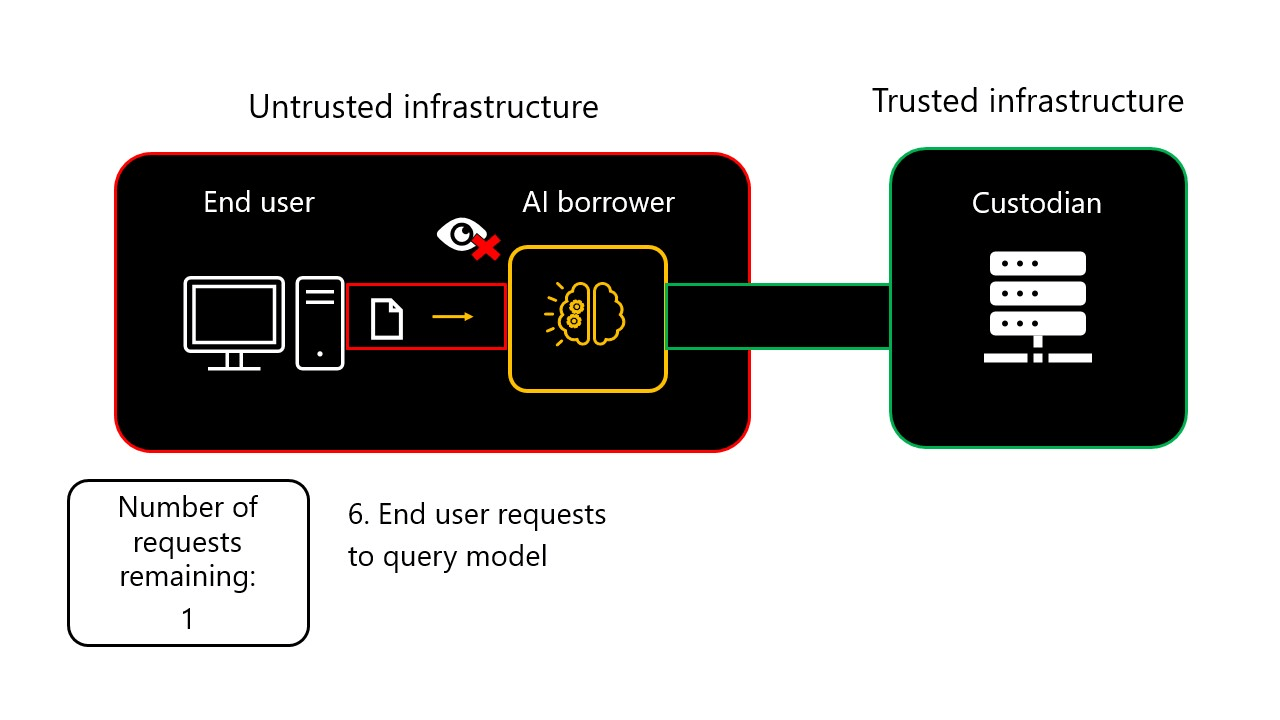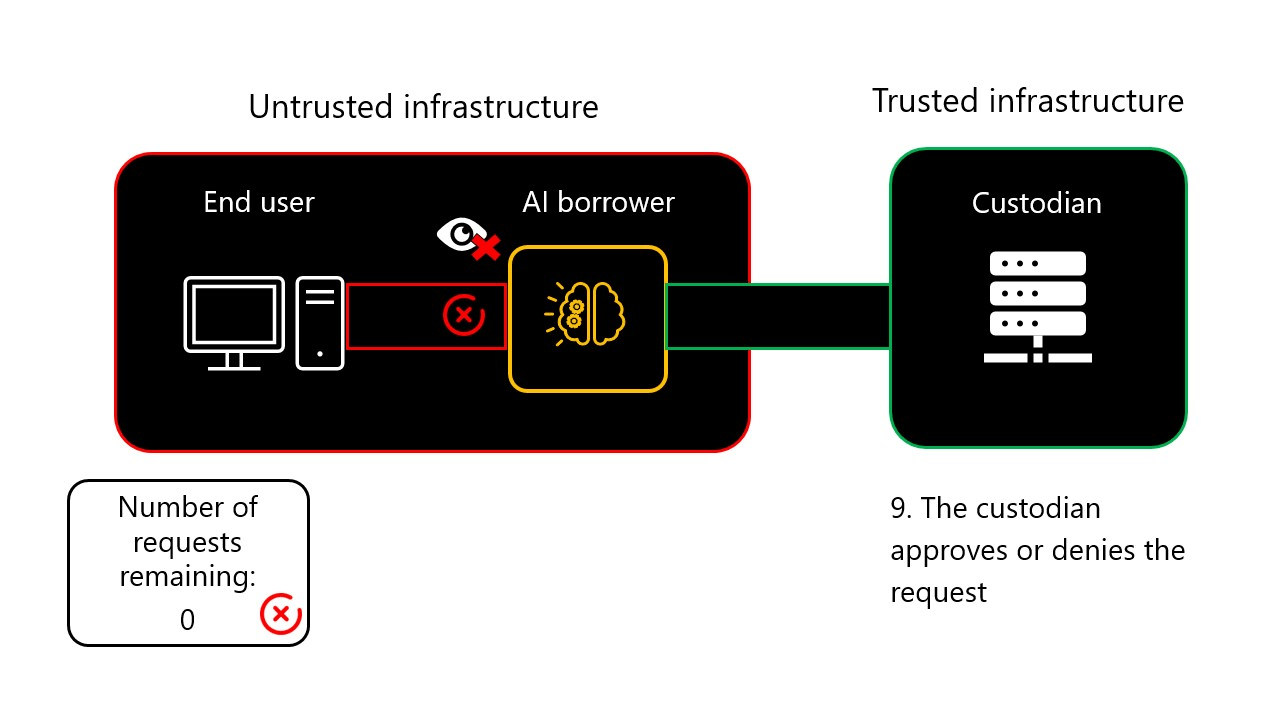
9-step AIGovTool workflow animation
Let’s now walk through the controlled AI consumption workflow cycle from start to finish:
- Custodian ships enclave server: The custodian will ship a server leveraging secure enclaves to the AI borrower.
- Custodian launches server: The custodian then launches their server, which will wait for a connection attempt from the enclave server. They specify an AI computing budget for the end user with the number of requests the end user will initially be able to make.
- Enclave server sends attestation report to custodian server: The enclave server is launched. It has no model preloaded. It pings the custodian server and shares cryptographic attestation assets to prove its authenticity. At the end of attested TLS, which is detailed below, the custodian will know:
- The enclave has been loaded with the right code and will have the DRM properties that the custodian expects.
- The enclave has the right security properties, in particular, hardware-based memory isolation, to prevent reading memory from extracting the model.
- A symmetric key has been negotiated, and the custodian can send the model without anyone else being able to access the data in clear, as only the enclave has the decryption key, and no one is able to extract it from the enclave.
- Custodian server sends model: Once the custodian has performed attested TLS, the model is securely sent to the enclave.
- End user query: The end user can request the enclave to consume the AI.
- Inference: The enclave verifies if the end user is within their computing budget, and if so, it performs inference and sends results back to the end user server.
- (Where applicable) Computing budget increase request: If the end-user has reached their computing budget threshold and wishes to make a new request, the enclave will request the custodian server to extend the end user’s AI computing budget.
- (Where applicable) Custodian response: The custodian will approve or deny the request to unlock additional requests for the end user.
- (Where applicable) Manual off-switch: The custodian can choose to manually shut down the custodian server at any time, making the enclave server obsolete. Any further queries to the enclave will fail.
Deploying and testing AIGovTool MVP
In order to test our AIGovTool MVP, please refer to our GitHub repo which gives you full access to the code and step-by-step instructions for deploying the solution on Azure Confidential VMs with Intel SGX.
Enclave dive-in
In order to understand how enclaves work, such as how data is protected by the hardware and how we can have cryptographic proof that we are communicating with an enclave with the right security properties, e.g., the right DRM code is loaded, we encourage you to look at the following resources:
- Our technical documentation for our collaboration with FLI
- Our series Confidential Computing explained, where we explain how enclaves work, walking you through how to code a key management system (KMS) with Intel SGX
Conclusions
This collaboration has laid the foundation of hardware-enforced AI governance. We have developed a POC of an AI deployment solution to guarantee consumption transparency, IP weight protection, and control mechanisms such as the off-switch button.
Note that while in this example, the weights are sent and protected to an enclave deployed on-premise by the AI borrower, the opposite can be achieved: data can be sent securely to an enclave hosted by the AI provider that will guarantee the confidentiality of the data.
This is what we focus on with BlindChat, our frontend client for a Confidential AI assistant that leverages BlindLlama, our GPU deployment solution with enclaves.
By developing and evaluating frameworks for hardware-enforced AI governance, FLI, and Mithril hope to help encourage the creation and use of AI regulation in order to keep AI safe without compromising the interests of AI providers, users, or regulators.
We would love for you to be part of our mission to make AI regulation enforceable. You can reach out and share your feedback with us through our Contact page. If you want to partner together on AI governance or explore specific use cases where privacy, transparency, and traceability are key, don’t hesitate to get in touch!


{kind=link}