
Deploy Transformers Models With Confidentiality
Learn how to deploy Transformers models, with privacy guarantees thanks to Confidential Computing!
In a Nutshell:
BlindAI, developed by Mithril Security, is an open-source Confidential AI solution that enables data scientists to deploy neural networks securely. Leveraging Confidential Computing with Intel SGX, BlindAI ensures end-to-end data protection and transparency. It simplifies the deployment of advanced models, like DistilBERT, while safeguarding the confidentiality and privacy of sensitive data.
I. Presentation of BlindAI
Our goal at Mithril Security is to democratize Confidential AI so that any data scientist can leverage sensitive data with privacy guarantees for data owners.
This is the reason why we have built BlindAI, an open-source, fast, and accessible inference solution for AI.
By using BlindAI, data scientists can deploy neural networks for various scenarios, from BERT models to analyze confidential documents, to medical imaging with ConvNets, through speech-to-text with WaveNet.
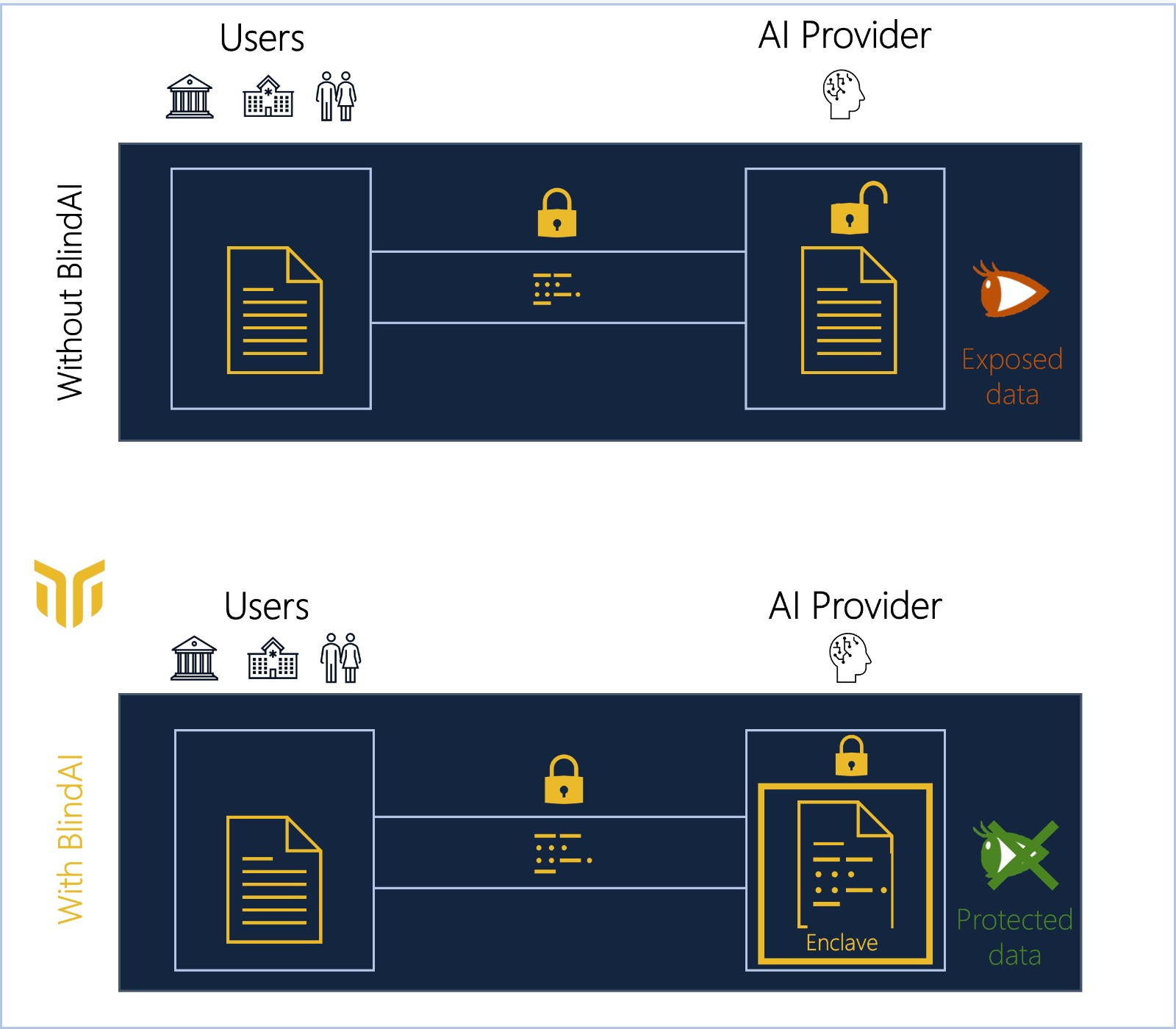
Our solution provides end-to-end protection by leveraging Confidential Computing with the use of Intel SGX. Confidential Computing enables the creation of enclaves, and secure environments, where sensitive data can be processed with guarantees that no outsider can have access to it. In addition, proof ensuring that the right code is loaded inside can be given so that data owners know that only trusted code will be executed on their data for transparency and to avoid backdoors.
Therefore, by using BlindAI, we help data scientists deploy models on sensitive data, for instance, medical or biometric data, and unlock markets blocked by security, privacy, or regulatory constraints.
We provide more information about Confidential Computing in our series Confidential Computing Explained.
Our solution comes in two parts:
- An inference server using Rust SGX. It loads ONNX models, exported from Pytorch or Tensorflow inside the enclave, and serves state-of-the-art AI models securely.
- A client SDK in Python, which allows users to securely consume AI models. It will check before sending anything that data will be only shared with services loading the right code and with the right security features, including end-to-end protection.
II. Getting started with Transformers and BlindAI
Overview
In this tutorial, we propose a quick start with the deployment of a state-of-the-art model, DistilBERT, for a simple classification task, with confidentiality guarantees using BlindAI.
To reproduce this article, we provide a Colab notebook for you to try.
In this article, we'll be using the managed Mithril Cloud as our BlindAI server, which means you don't have to launch anything locally.
A - Install BlindAI
You will need our Python SDK to upload a model and query it securely.
You can install it using PyPI with:
pip install blindaiInstall BlindAI
Or you can build it from a source using our repository.
B - Deploy your server
There are 3 different possible deployment methods. This documentation could be helpful for your reference.

C - Upload the model
For this tutorial, we want to deploy a DistilBERT model for classification within our confidential inference server. This could be useful, for instance, to analyze medical records in a privacy-friendly manner and compliant way.
Because our inference server loads ONNX models, we have to first export a DistilBERT in ONNX format. Pytorch or Tensorflow models can be easily exported to ONNX.
Step 1: Load the BERT model
from transformers import DistilBertForSequenceClassification
# Load the model
model = DistilBertForSequenceClassification.from_pretrained("distilbert-base-uncased")Load the BERT model
For simplicity, we will take a pre-trained DistilBERT without fine-tuning it, as the purpose is to show how to deploy a model with confidentiality. In future articles, we will show examples that go from training to deployment.
Step 2: Export it in ONNX format
Because it uses tracing behind the scenes, we need to feed it an example input.
from transformers import DistilBertTokenizer
import torch
# Create dummy input for export
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
sentence = "I love AI and privacy!"
inputs = tokenizer(sentence, padding = "max_length", max_length = 8, return_tensors="pt")["input_ids"]
# Export the model
torch.onnx.export(
model, inputs, "./distilbert-base-uncased.onnx",
export_params=True, opset_version=11,
input_names = ['input'], output_names = ['output'],
dynamic_axes={'input' : {0 : 'batch_size'},
'output' : {0 : 'batch_size'}})Export the model in ONNX format
Now that we have an ONNX file, we are ready to upload it to our inference server.
import blindai
import uuid
api_key = "YOUR_API_KEY" # Enter your API key here
model_id = "distilbert-" + str(uuid.uuid4())
# Upload the ONNX file to the remote enclave
with blindai.Connection(api_key=api_key) as client:
response = client.upload_model("distilbert.onnx", model_id=model_id)Upload the model to our BlindAI Cloud
Now that the model is loaded inside, we just have to send data to get a prediction.
D - Get a prediction
The process is as straightforward as before; simply tokenize the input you want before sending it.
from transformers import DistilBertTokenizer
# Prepare the inputs
tokenizer = DistilBertTokenizer.from_pretrained("distilbert-base-uncased")
sentence = "I love AI and privacy!"
inputs = tokenizer(sentence, padding = "max_length", max_length = 8, return_tensors="pt")["input_ids"]Prepare the inputs to be sent.
Now we simply have to create our client, connect, and send data to be analyzed. In the same fashion as before, we will create a client and simply send data to be analyzed with the proper communication channel.
import blindai
with blindai.connect() as client:
response = client.predict(model_id, inputs)Get prediction with a server in simulation mode
And voila! We can benefit from a state-of-the-art model with confidentiality guarantees: no need to fear data exposure anymore when using external AI solutions!
You can check the correctness of the prediction by comparing it to results from the original Pytorch model provided by the Transformers library:
>>> response.output[0].as_flat()
[0.0005601687589660287, 0.06354495882987976]Results with BlindAI
>>> model(inputs).logits.detach()
tensor([[0.0006, 0.0635]])Results with original model in Pytorch
We hope you enjoyed our first article! We have many more articles on the way, from confidential Speech-to-text to medical image analysis. To support Mithril Security, please star our GitHub repository!
Want to turn your SaaS into a zero-trust solution?


{kind=link}