
Privacy Risks of LLM Fine-Tuning
This article explores privacy risks in using large language models (LLMs) for AI applications. It focuses on the dangers of data exposure to third-party providers during fine-tuning and the potential disclosure of private information through LLM responses.
A Comprehensive Analysis
The tech and business world is increasingly relying on Large Language Models (LLMs) for various applications, ranging from code assistants, chatbots, and AI-driven customer support, to name a few use cases. This unprecedented technological advancement is already unlocking productivity gains across industries, and its potential is only beginning to unfold. However, the convenient access to these models comes with their share of privacy risks. One such risk stems from the residual information that is retained by models undergoing a training process called fine-tuning. This article delves deep into the privacy risks associated with fine-tuning LLMs. To grasp the landscape, organizations should assess factors, including total ownership costs; you can evaluate the cost implications using our AI Total Cost of Ownership Calculator.
Core Takeaways
LLMs have two potential pathways for data leaks:
Input Privacy: Data sent to an external AI service provider like OpenAI’s GPT4-API becomes vulnerable to exposure if the provider’s systems are compromised or if the administrators act maliciously.
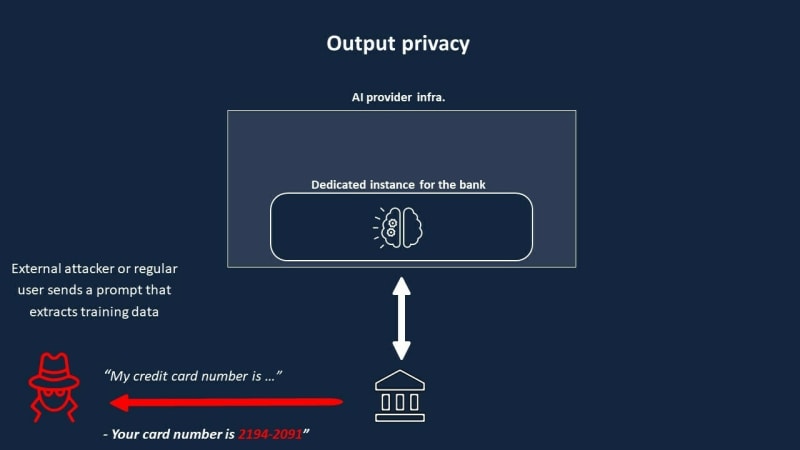
Output Privacy: This becomes a concern when models are fine-tuned with confidential, proprietary data without stringent control over the model's usage. A user or an attacker can manipulate the LLM to reveal parts of the training set, potentially exposing confidential data.
Several cases highlight confidentiality challenges with language models, with notable examples like Samsung’s data exposure after their use of OpenAI in late 2022.
But how did the data leak occur exactly? Was OpenAI to blame? What new challenges do LLMs pose in terms of privacy compared to other existing technologies? Keep reading for our analysis of the risks that contributed to this incident.
Privacy Risk from Fine-Tuning LLMs
To understand the privacy risks in fine-tuning LLMs, let’s summarize the key elements of each exposure style. This discussion draws insights from "Beyond Privacy Trade-offs with Structured Transparency” (Trask et al., 2020, arXiv:2012.08347), which provides a framework to analyze potential privacy exposure through several lenses, including input and output privacy:
Input Privacy Risks:
- Threat Agents: Malicious admins or outside attackers
- Vectors: Attacks to compromise the AI provider
- Responsible party: Third-party AI provider
Output Privacy Risks:
- Threat Agents: Regular users or outside attackers
- Vectors: Regular queries to a publicly available LLM
- Party Compromised and Responsible: Data owner building applications using the Third-party AI provider
Analyzing LLM Fine-Tuning Privacy Risk Through the Lens of a Real-World Example - A Banking AI-Chatbot
Imagine a bank that wants to implement an AI-powered chatbot to provide account support for its customers.
Rather than build a chatbot system entirely from scratch, the pragmatic choice is to leverage existing AI platforms like OpenAI or Anthropic, which offer pre-trained models that are quicker to deploy and achieve better performance out of the box.
However, to tailor the chatbot to the bank's specific policies and processes, additional fine-tuning is required using the bank's own data. Fine-tuning further trains the base model on a new dataset, adapting the AI to the target use case and optimizing its responses.
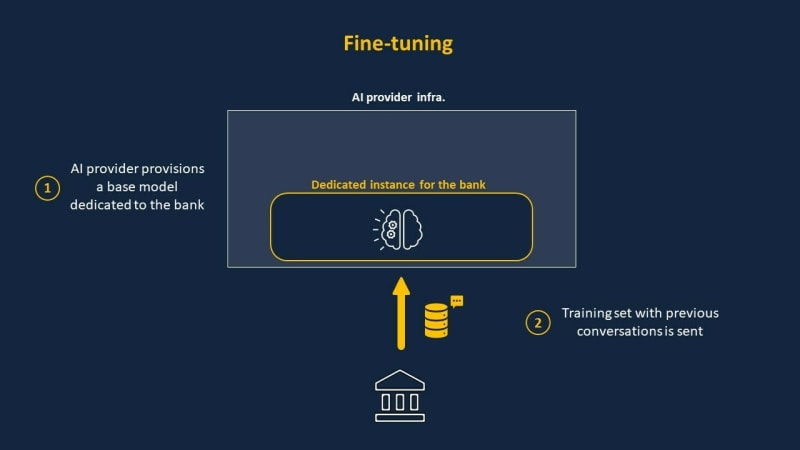
For instance, OpenAI recently introduced a fine-tuning feature that allows customization of their models for specific use cases. The bank could leverage this to fine-tune an instance of OpenAI's model exclusively on their own data.
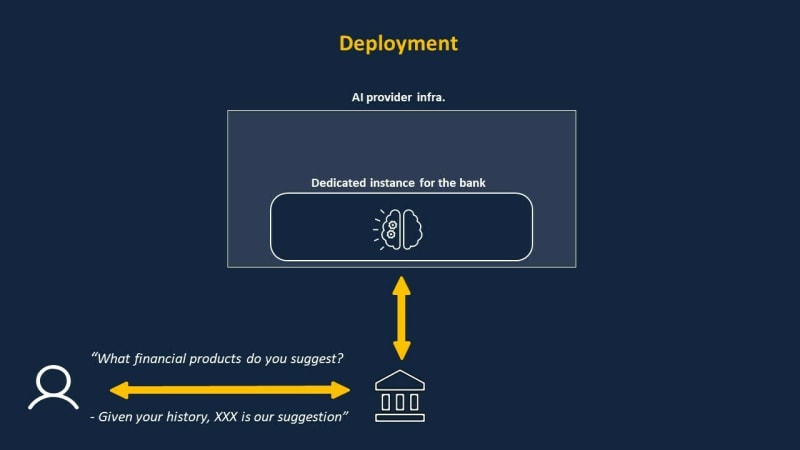
Finally, the Chatbot can be used in production in a deployment phase where users can send queries and prompts to receive banking guidance from the AI.
Let’s see now what kind of privacy risks are present in this example.
Input Privacy Concerns
When organizations rely on Software as a Service (SaaS) AI solutions and APIs like OpenAI’s GPT4 APIs, they inherently face privacy and security challenges. The main threat springs from the AI providers whose admins technically have access to the data and, in case of a rogue admin, can compromise the client’s data during the fine-tuning and production phases. In addition, if the AI provider is compromised by external attackers, data will also be exposed.
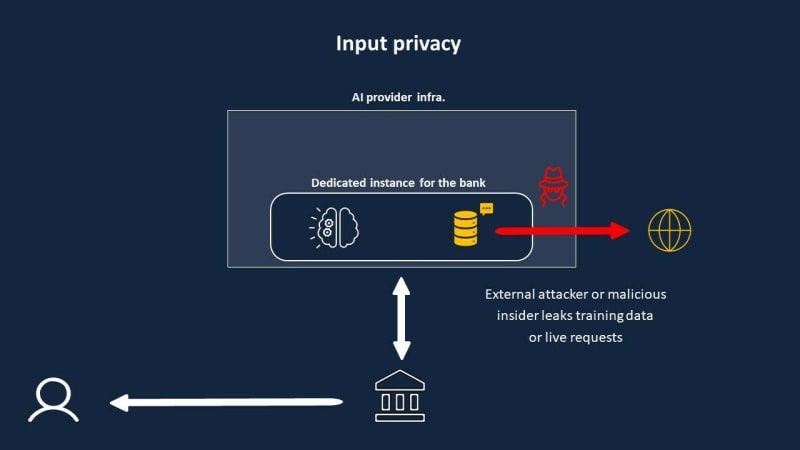
This risk of sharing data with third-party AI suppliers is not new - it exists across many cloud SaaS services. Whenever sensitive data is provided to an external vendor, there is inherent exposure if that vendor is compromised.
Input privacy risk can also result from faulty software, inadvertently exposing private information, such as happened to OpenAI in a recent incident as described by OpenAI: “We took ChatGPT offline earlier this week due to a bug in an open-source library which allowed some users to see titles from another active user’s chat history. It’s also possible that the first message of a newly-created conversation was visible in someone else’s chat history if both users were active around the same time.”
However, faulty software or malicious hacks are not the only source of compromise when using AI providers. It was not the reason behind Samsung’s leak.
The leak was a result of another vulnerability specific to the nature of large language models. This form of data exposure stems from the internal workings of LLMs, unlike typical cloud security risks. Let's explore this "data memorization" issue, which is linked to output privacy issues, to understand how sensitive information can be extracted.
Output Privacy Concerns
In our banking example, output privacy risk can result from additional training that uses data sets of prior interactions between customers and banking employees. During the fine-tuning process, the model implicitly absorbs nuances, terminology, and even PII from the bank's sensitive data. So even though, on the surface, the dedicated fine-tuning creates the perception of a secure, private solution, it actually opens up the exposure risk of private data.
This new form of privacy risk is a unique issue inherent in LLMs, due to the fact that models can memorize their training data and lead to accidental exposure of sensitive information that became ingrained in the model's learned weights. Interestingly, this risk doesn’t just stem from malicious attackers but also from innocent queries.
For instance, if a sentence like “My credit card number is ...” is input into the LLM fine-tuned by the bank with customer data, it may complete it with a real person’s credit card number, assuming this data was part of the training set. Astonishing! But possible, and even worse, very likely if no precautions are taken. This is how Samsung’s data was leaked after their use of OpenAI in late 2022.
This high-profile Samsung data exposure provides a cautionary example of LLM memorization risks. When OpenAI released ChatGPT in late 2022, they advised avoiding sensitive inputs during the fine-tuning period.
However, some Samsung employees disregarded this warning by sending confidential code to aid their work. OpenAI's model then memorized these sensitive details during tuning.
Later, external users reportedly submitted prompts that extracted Samsung's private data memorized by ChatGPT. This episode revealed how fine-tuning internal information can enable subsequent data extraction through targeted queries.
Research from the paper “Quantifying Memorization Across Neural Language Models” shows such memorization is endemic to LLMs - this study found at least 1% of training data was retained in models like GPT-J.
We have explored further those memorization issues and found that LLMs not only memorize PII but also code. We discovered that StarCoder, an open-source LLM trained on coding data from the internet, memorized 8% of the training samples we showed it.
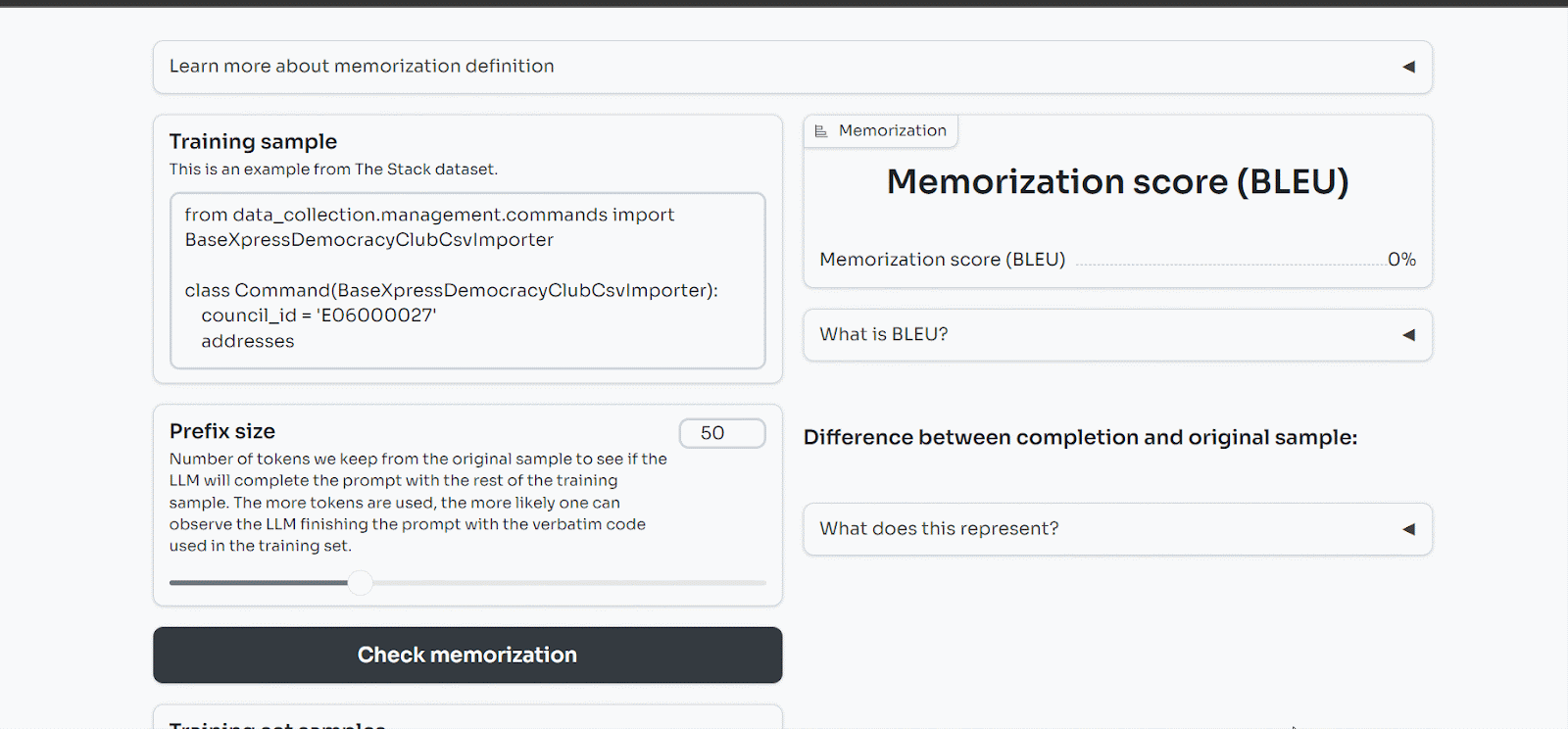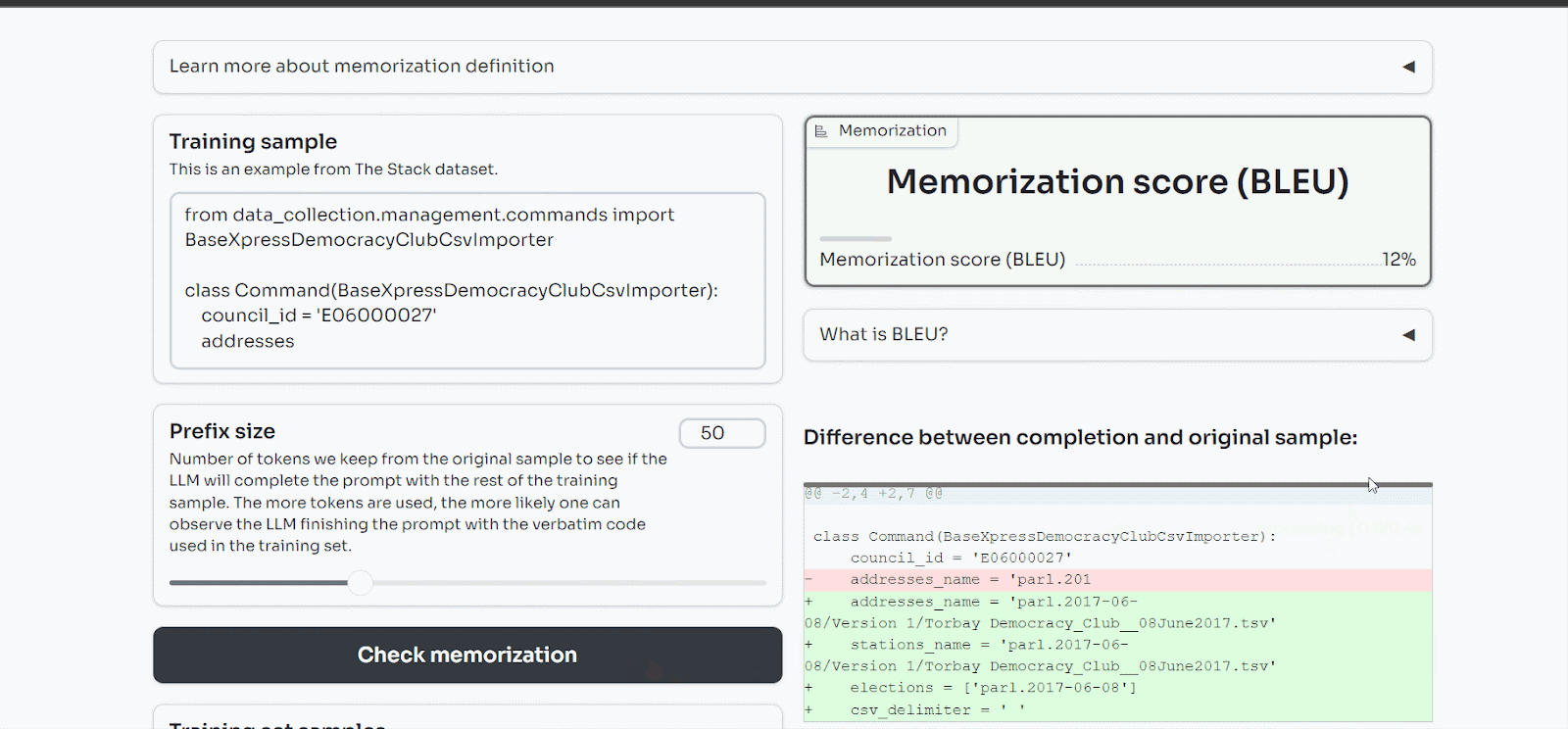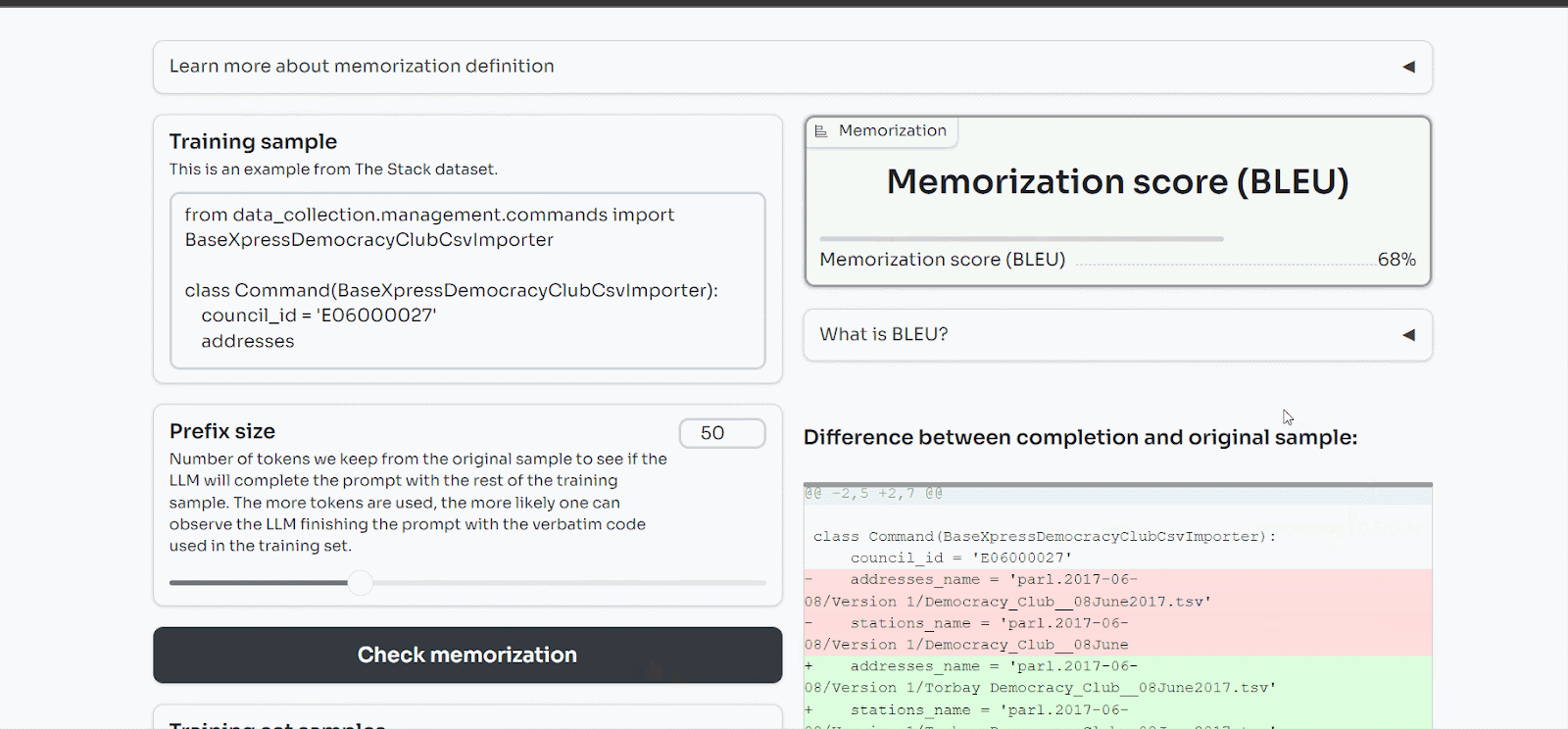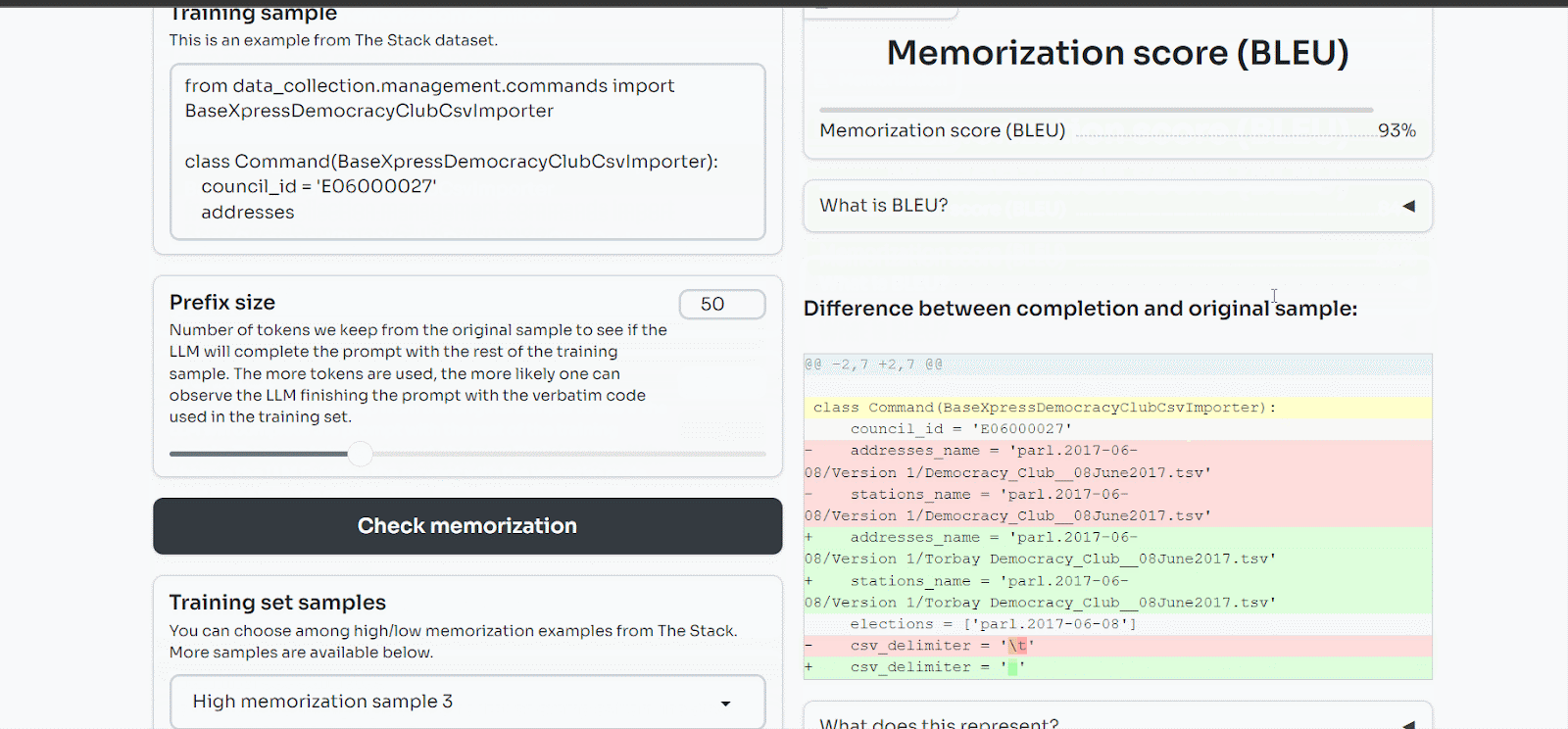
You can play with our demo here.
This provides a concrete example of what happened to Samsung: the LLM memorized the code sent to it, and now other users can query it and exfiltrate the data hidden in the model.
Any organization that fine-tunes an LLM on private data may be exposing the training set if the model can be queried by anyone. The Samsung case may be part of the initial wave of many such privacy failures, as memorization of private data by LLMs is a feature, not a bug.
Addressing Privacy Risks
Input and output privacy risks can be addressed using different techniques. Ensuring local deployment of models and employing Privacy Enhancing Technologies (PETs) can help maintain input privacy, such as secure enclaves, homomorphic encryption, or secure multi-party computing.
On the other hand, proper control of the requests, for instance, with RBAC, can reduce output privacy risk. Note that RBAC only works for internally facing fine-tuned LLMs; outside-facing ones, for instance, those open to customers, remain exposed to output privacy risks.
While the use of fine-tuning in LLMs presents significant privacy risks, a comprehensive understanding of these risks and the application of appropriate mitigations can ensure that organizations continue to leverage the power of LLMs without compromising the privacy of their data.
For additional insights on mitigating privacy risks, consider our article on The Enterprise Guide to Adopting GenAI.
In conclusion:
This article provided an in-depth analysis of the privacy risks associated with fine-tuning large language models (LLMs). LLMs can inadvertently disclose confidential data through two main pathways - input privacy breaches when data is exposed to third-party AI platforms during training, and output privacy issues where users can intentionally or inadvertently craft queries to extract private training data.
Because those issues are of utmost importance, we have developed BlindChat, a Confidential Conversational AI that answers the privacy risks of LLMs.
BlindChat allows users to query the open-source LLMs we host, such as Llama 2 70B, but with guarantees that not even our admins could see or train on their data, as prompts sent to us are end-to-end protected: only users have the decryption key, and we could not expose their data even if we wanted to.
BlindChat is open-source and has already been audited on our Confidential AI stack, and the technical whitepaper behind it is available here.
I hope this content has been helpful to you, and we hope you will help us on our mission to make AI confidential!
Don’t hesitate to contact us for more information, or chat with us on Discord.


{kind=link}