
The Enterprise Guide to Adopting GenAI: Use Cases, Tools, and Limitations
Generative AI is revolutionizing enterprises with enhanced efficiency and customer satisfaction. The article explores real-world applications and deployment options like SaaS, on-VPC commercial FMs, and on-VPC open-source FMs, emphasizing the need for data protection.
Key Takeaways:
Generative AI's real-world applications are transforming industries by enhancing efficiency and creativity. Deploying AI models is a complex task due to technical challenges, cost considerations, and privacy issues. Enterprises can choose from deployment options such as:
- On-VPC Commercial FMs, offering privacy but potentially lacking features.
- SaaS Commercial FMs, providing quick, feature-rich solutions but with privacy risks.
- On-VPC Open-source FMs, allowing full control but requiring substantial expertise and investment.
Few innovations have sparked as much excitement and potential as Generative AI. Large Language Models (LLMs), particularly, are creating a buzz with their early but transformative impact on enterprises. LLMs are reshaping business operations by enhancing efficiency, increasing customer satisfaction, and fostering creativity.
Integrating LLMs can be a complex technical challenge in the ever-changing AI landscape. Even experienced professionals may find it difficult to understand the intricate details of implementing Generative AI. Nonetheless, it is critical for enterprises to keep up with these innovations and harness their potential.
In this article, we explore the different ways to deploy LLMs, analyzing the pros and cons of each.
Real-World Applications: Enterprise Use Cases of Generative AI
As a large enterprise, you may be wondering: why invest in Generative AI? Is it worth the effort?
While we are still in the early adoption phase, there are several promising data points that highlight the potential of LLMs. We will show three use cases of enterprise adoption.
Wealth management productivity with Morgan Stanley
Morgan Stanley used OpenAI's GPT4 to make an internal chatbot. It lets wealth management advisers get important information fast. This has improved customer service and greatly increased efficiency. Overnight, it was as if every employee had gained access to the expertise of the most knowledgeable wealth manager at Morgan Stanley. Today, 200 employees use it daily to rapidly find information to help clients.
Developer productivity with Stripe
Stripe adopted GPT4 to support its users– specifically, developers seeking extensive technical documentation. Developers can now ask technical questions or seek troubleshooting support from the chatbot, and Stripe gives them the most relevant information from the developer docs as well as where to find it, raising customer satisfaction and reducing troubleshooting time.
Increased learning ability with Duolingo
Duolingo has increased its learning ability by adopting GPT4, entering the education landscape with new features in Duolingo Max. It includes two AI-powered features: an "explain my answer" option and a "roleplay" chatbot in French and Spanish, allowing users to practice conversing in real-time.
Generative AI's ability to understand human language is not just a trend; it has the potential to disrupt entire industries, especially since most of our society relies on natural language interaction.
Now, the big question is not "if" but "how."
Deploying LLMs as an enterprise
All of these example enterprises used OpenAI’s GPT4, which represents an often-heard-about way to deploy LLMs, but there are several ways to adopt it, each with its set of pros and cons.
In the rest of this article, we will consider the scenario where the enterprise is on a VPC (Virtual Private Cloud). This means that the enterprise uses the Cloud of one of the major providers, where it enjoys its own (virtually) isolated and dedicated part of the Cloud.
This assumption is key to better understanding the different deployment models, in other words, how to get a Foundational model (FM) up and running to start leveraging Generative AI. A Foundational model is a base model that is able to analyze text and generate answers based on prompts provided by users.
You can think of an FM as the brain of the operation and where the innovation lies. There is still often a need to have other classical elements, such as a database, to store documents (vectors) and interact with them through a web interface.
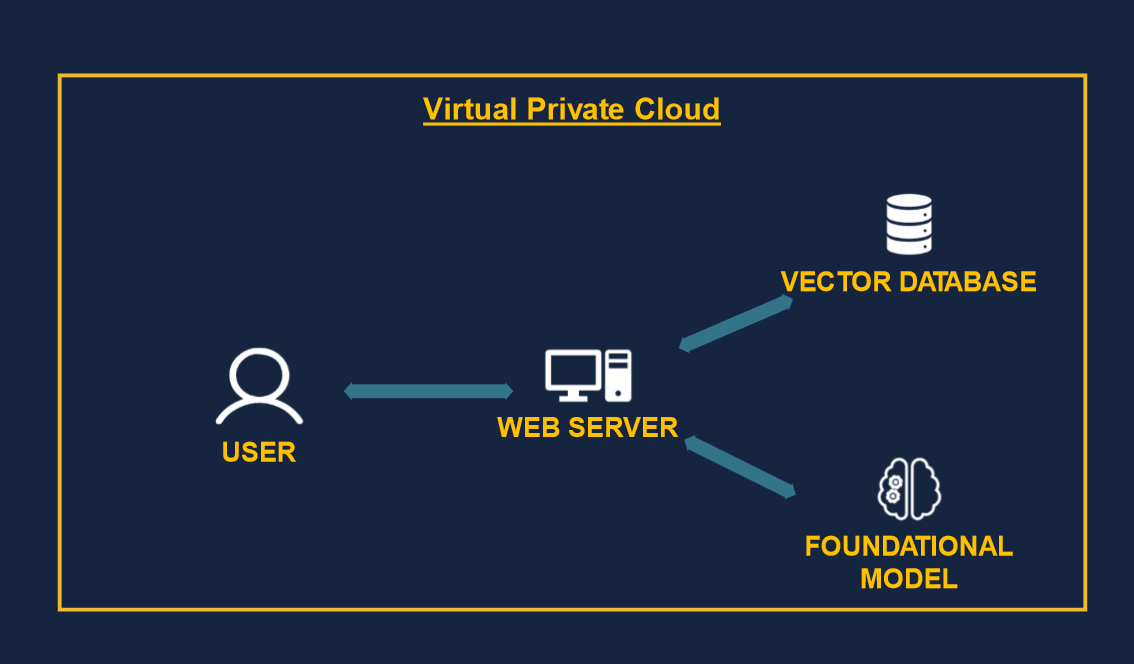
For instance, one way to implement the Morgan Stanley use case, where we have an FM that helps centralize knowledge and query with natural language, could be:
- A Foundational model is used to find the most relevant piece of information to answer a query and generates the answer in natural language.
- A vector database is used to store knowledge about the company to be retrieved by collaborators.
- A web server is used to glue the different components together and display a nice user interface for the end user.
This illustrates a simple application, but the FM is key: it's the brain of the entire operation, and its selection and deployment are critical. Think of it as the engine on which the car (app) is constructed.
Therefore, throughout the rest of this article, we will provide you with criteria to help you choose the Foundational model that suits you best.
We don’t think there is necessarily a universally better approach, so we will only provide elements for you to choose the most appropriate solution. We have provided several criteria to evaluate each solution:
- Model performance: the LLM's ability to perform various tasks
- Cost structure: whether you pay per request or per GPU.
- Setup time: the time required to deploy the model and begin using it.
- Setup complexity: the level of expertise required to get the model running in production
- Features: the range of features offered
- Privacy control: the extent of control over data exposure to external third parties.

Most of the work done around a Foundational model is standard, such as managing a database or a web server. However, the essential task is getting a Foundational model operational. It's a vital but challenging step that may be complex and slow down both experimentation and broad deployment...
On-VPC deployment of Commercial FMs
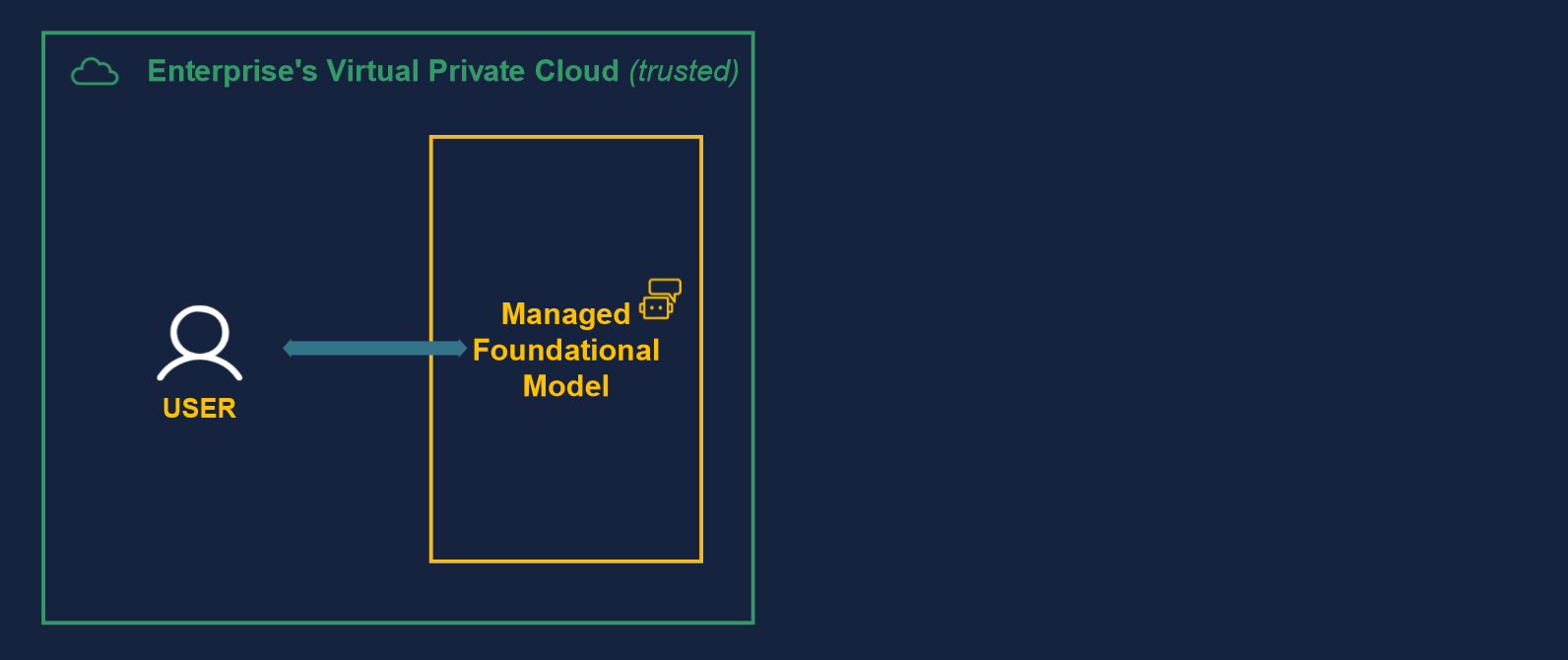
One way to get an FM running up and running is to deploy it inside one’s enterprise Virtual Private Cloud (VPC). This approach primarily addresses privacy and security concerns, as no data exits the VPC. Depending on the solution selected, it can also be relatively quick to implement.
We distinguish two main families of PaaS solutions:
- Cloud provider-based solutions like Azure OpenAI Service or Google Vertex AI.
- AI pure player-based solutions like Cohere, Anthropic, AI21 Labs, etc., are available on Cloud marketplaces, e.g., AWS Sagemaker.
Cloud provider-based solutions have the advantage of being an integral part of their offering, and it can be relatively easy to get started. For instance, they might not require the enterprise to get a GPU quota, which is often a key obstacle to adoption.
Billing is typically based on the number of requests, specifically the number of input tokens (i.e., the size of the text sent to the FM) and generated tokens (i.e., the size of the answer).
Solutions offered by specialized AI companies may necessitate that enterprise customers first set up a cluster of GPUs before deployment. This process can be expensive, time-consuming, and demand specialized engineering knowledge.
There is a wide spectrum of deployment methods, from requiring the enterprise customers to prepare a Kubernetes cluster before deploying the FM on it to being distributed by marketplaces like AWS Sagemaker. The way enterprises are billed is based on the computing they consume, e.g., per GPU per hour used to run the FM.
Requiring the enterprise to source the GPUs can be challenging as it often forces the IT team to ask for a GPU quota. Additionally, those GPUs are often underutilized as it requires technical expertise to fully leverage GPUs and constant large demand to fully leverage parallelization.
For companies that provide both SaaS and On-VPC deployment, we notice that there is a discrepancy between both offers, where the SaaS solution is often more feature-rich.
If we look at OpenAI vs. Azure OpenAI Service, for instance, we observe that more models are covered on OpenAI (Whisper for Speech-to-Text is not available on Azure), and some features such as Chat or Plugins are not available.
SaaS consumption of Commercial FMs
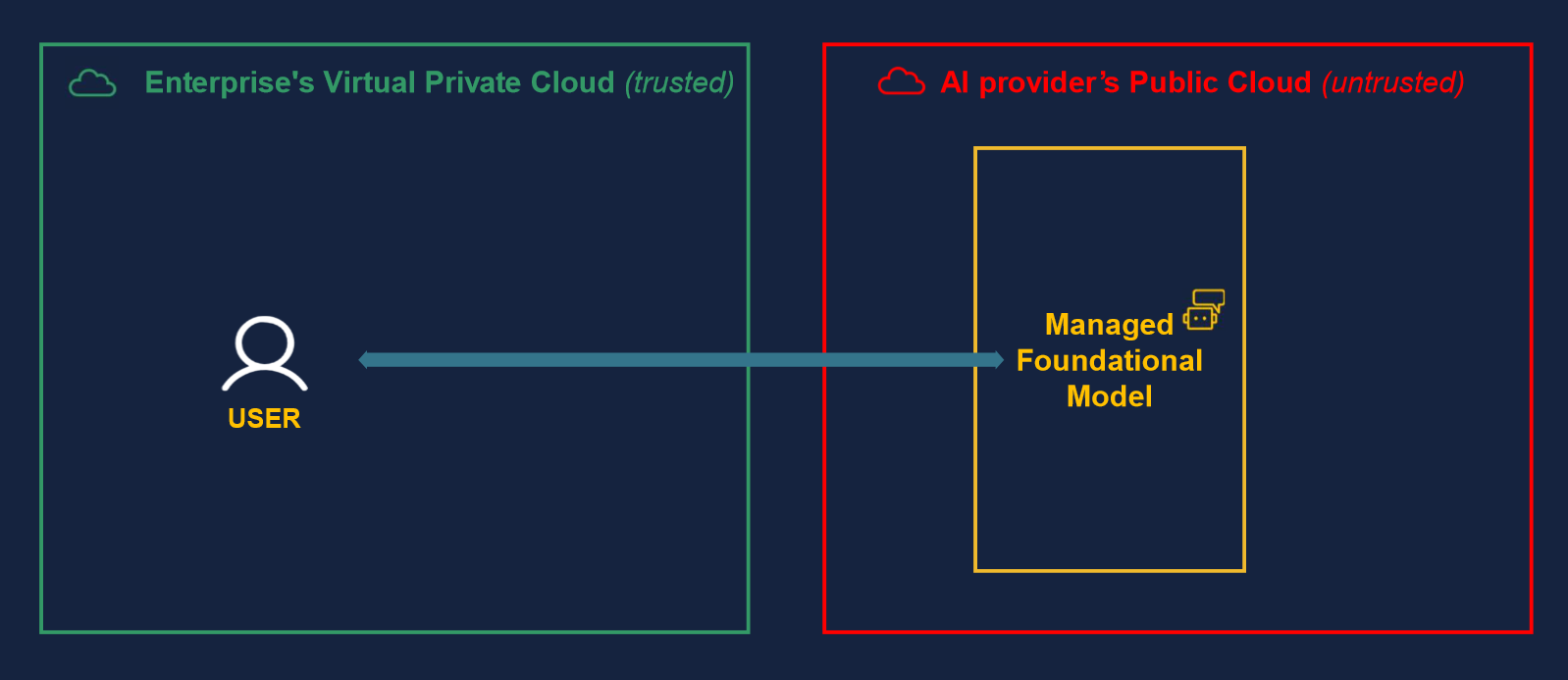
SaaS (Software as a Service) is a deployment model where the Foundational model is hosted outside of the enterprise VPC, and data is sent there.
It has the main advantage of requiring no provisioning, deployment, and maintenance effort from enterprises, as the hardware/software stack is fully managed by the AI provider, e.g., OpenAI, Anthropic, Cohere, etc. Enterprises are not required to demand GPU quotas and manage those, which can be a significant reduction in time and complexity,
Because the AI provider centralizes the infrastructure, it is also easier to push features and have more up-to-date models as models can be continuously trained. Additional benefits include built-in features such as safety checks, which can be packaged and updated continuously to ensure a safe user experience.
However, data leaves enterprises’ VPC, and this can pose privacy issues.
The situation with Samsung demonstrated how challenging it can be for enterprises to guarantee data privacy once it leaves their control. It is today quite difficult to have any guarantees over what happens to one’s data as soon as it leaves one’s infrastructure.
Security certifications such as SOC 2 are often necessary but far from being sufficient, especially when we talk about sending a lot of corporate data to a third-party AI provider.
From a cost perspective, SaaS solutions can be much more cost-efficient as AI vendors can rent GPUs for a long period, thereby benefiting from reduced prices. They can also fully optimize their resources by serving multiple customers, unlike enterprises that might rent on the spot and underutilize their GPUs.
On-VPC deployment of Open-source FMs
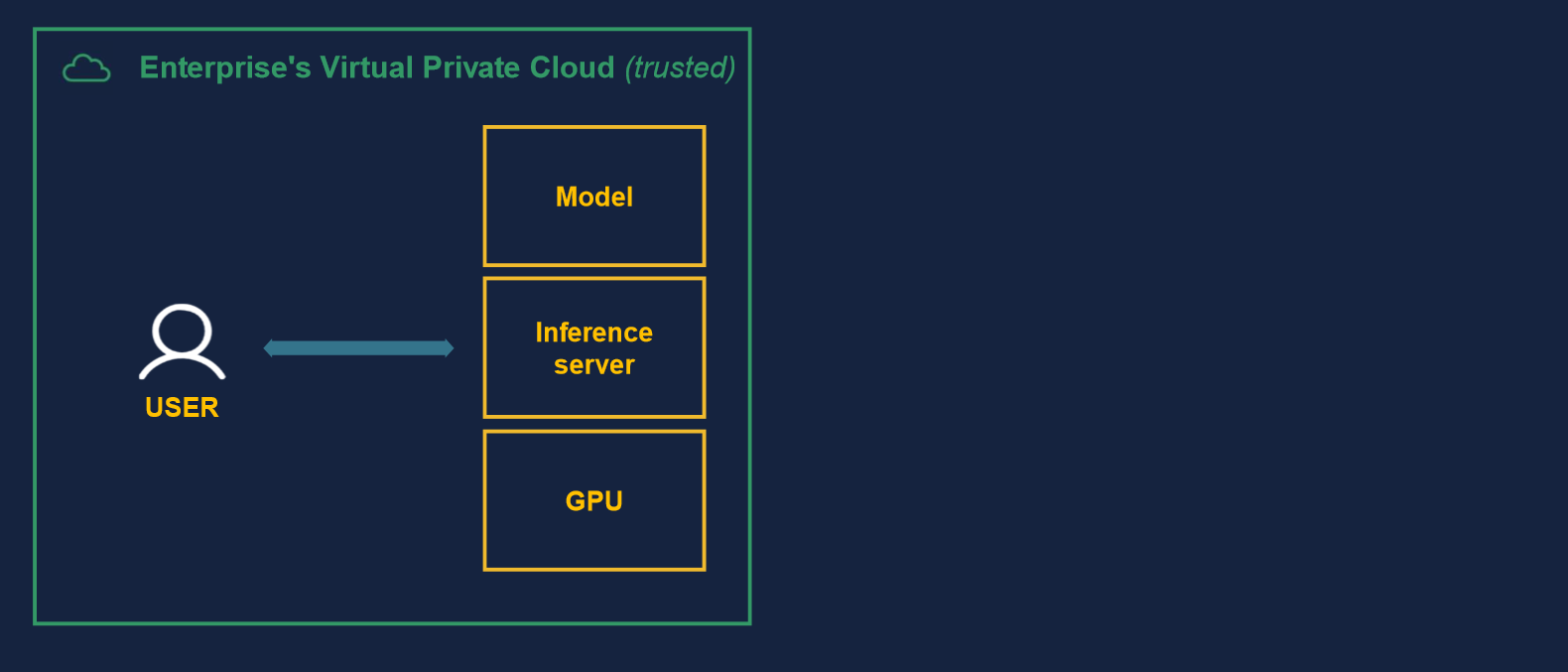
Finally, the last way is to deploy an open-source model inside the enterprise infrastructure. This provides total control over data governance. Cost can be much more easily controlled, too, as there are few external dependencies to third parties.
However, this is the most complex deployment to pull off as it requires a lot of internal expertise and infrastructure investment. Even if great open-source tools such as Hugging Face exist, deploying the model still requires engineering expertise, GPU quotas, and so on.
Sourcing the right hardware that is performant but not too expensive, configuring deployment servers, managing the AI model lifecycle, fine-tuning it, etc., are all tasks the enterprise now has to do on its own.
Open-source models seemed to lag behind the closed-source solutions, but Meta’s Llama 2 model has shown very good performance (even though there are scenarios it still does not cover well, such as code analysis).
Fine-tuning these models on private data can enhance performance, but some features, such as alignment and safety checks, may be challenging to develop internally.
This approach may have the highest upfront cost but generally results in the lowest variable expenses...
Conclusion
In conclusion, we have seen several modalities to have a Foundational model deployed and usable by an enterprise. Each choice has its pros and cons.
- SaaS consumption of Commercial FMs like OpenAI offers feature-rich, fast, and cost-efficient solutions without requiring significant in-house expertise. It's an excellent option for quick deployment with minimal upfront cost. It comes, however, at the expense of privacy issues and requires trusting external companies with enterprise data.
- On-VPC deployment of Open source FMs allows for complete control but requires substantial investment and expertise. It’s suited for companies aiming for customization with strong tech teams to handle it, as seen with Bloomberg, which developed internallyBloombergGPT.
- On-VPC Commercial FMs present a balanced approach, keeping data within the enterprise VPC, simplifying deployment, and delivering good performance, even though they might not be as good as the SaaS ones.
We recognize that SaaS consumption of Commercial FMs holds significant promise for most enterprises. With the advantages of cost-efficiency through centralized GPUs, simplified onboarding with no infrastructure effort, and rich features, it's an appealing option.
However, privacy issues deter enterprises from choosing that option.
That is why we are building BlindBox, an open-source secure enclave tooling that enables enterprises to consume external AI solutions without exposing at any time their data in clear, thanks to end-to-end encryption. You can find more about different use cases, from confidential medical voice notes analysis to code completion with privacy guarantees.
We hope this article has been useful and will help you with your Generative AI adoption! If the potential of Confidential AI resonates with you or if you're contemplating professional consultation to adopt FMs, reach out to us.
Want to learn more about Zero-Trust LLM deployment?
Image credits: Edgar Huneau


{kind=link}