
AICert v1.0 - Open-Source AI Traceability Tool for Verifiable Training
A year ago, Mithril Security exposed the risk of AI model manipulation with PoisonGPT. To solve this, we developed AICert, a cryptographic tool that creates tamper-proof model cards, ensuring transparency and detecting unauthorized changes in AI models.
We're thrilled to share our latest project, AICert, supported by the Future of Life Institute. For more details on our motivations, check out the article on the FLI blog we co-authored.
TL;DR:
- A year ago, Mithril Security gained attention with its "Model Poisoning" demo, which highlighted the significant risks posed by AI supply chain attacks. The demo showcased how AI models could be easily manipulated for malicious purposes without detection.
- The core issue lies in the lack of a verification mechanism for model identity and traceability. Currently, there’s no reliable way to ensure a model’s provenance or verify that it is the model claimed by its publishers.
- We propose AICert, a solution leveraging cryptographic virtual Trusted Platform Modules (vTPMs) to create tamper-proof model cards. These cards bind training datasets and processes to the model, ensuring transparency in AI development and making any unexpected changes detectable.
From Whistleblower to Solution Developer
A year ago, Mithril Security brought attention to a critical but overlooked AI risk: model poisoning. The demo showcased how AI models could be easily manipulated for malicious purposes (such as spreading fake news) without detection.

Though a year has passed, the risk still looms large. Users still lack a reliable way to verify the identity and integrity of AI models, especially those hosted on open platforms. There is no mechanism to ensure the model hasn't been tampered with.
Building upon our findings, Anthropic’s paper, Sleeper Agents: Training Deceptive LLMs that Persist Through Safety Training, took the concept of malicious models even further. They trained a "sleeper agent" model that initially behaves as expected but later switches to undesirable actions, much like a human sleeper agent. Both cases highlight a traceability problem: models can be secretly modified without detection.

Given our expertise in AI security and enclave technology—which provides cryptographic traceability—we took on the challenge of developing a solution for model traceability based on secure enclaves.
An Enclave-Based AI Bill of Materials (AIBOM)
So, what is an AIBOM?
Inspired by the Bill of Materials used in traditional manufacturing, the AI Bill of Materials (AIBOM) documents the origin and key characteristics of an AI model while providing cryptographic proofs to ensure its integrity. As AI systems become more integral to critical applications, ensuring transparency and security is vital.
Today, even though some models are open-source, there is no guaranteed way to certify how they were trained. While some AI providers share details about their training processes, weights, and input data, there’s no way to verify this information. We argue that open-sourcing alone is insufficient to guarantee model traceability. (You can read more about this in our blog post: Open Source is Not Enough.)
For an AIBOM to be effective, it must cryptographically link the model’s weights with its training process (code and input data). This ensures that any alteration to the model can be detected immediately, maintaining the authenticity of the AIBOM and the integrity of the AI system.
To meet this need, we developed AICert, a solution that creates secure AIBOMs enforced through cryptographic methods. Each iteration of the model—whether during training or deployment—is recorded and certified, allowing users and auditors to verify its origins and integrity. This not only boosts user confidence but also streamlines regulatory compliance.
How Does AICert Work?
AICert enables developers to create unforgeable model cards that cryptographically certify the model's properties. They can offer an AI Bill of Materials documenting the data and code used, making it harder to inject backdoors into the model’s weights. This also (finally) enables AI providers to prove that their model wasn’t trained on copyrighted, biased, or non-consensual personal data.
The core idea behind AICert is to create certificates that cryptographically bind model weights to the training data and code. End-users can then verify these AI certificates, ensuring the model they’re interacting with was trained as claimed, reducing concerns about copyright, security, or safety issues.
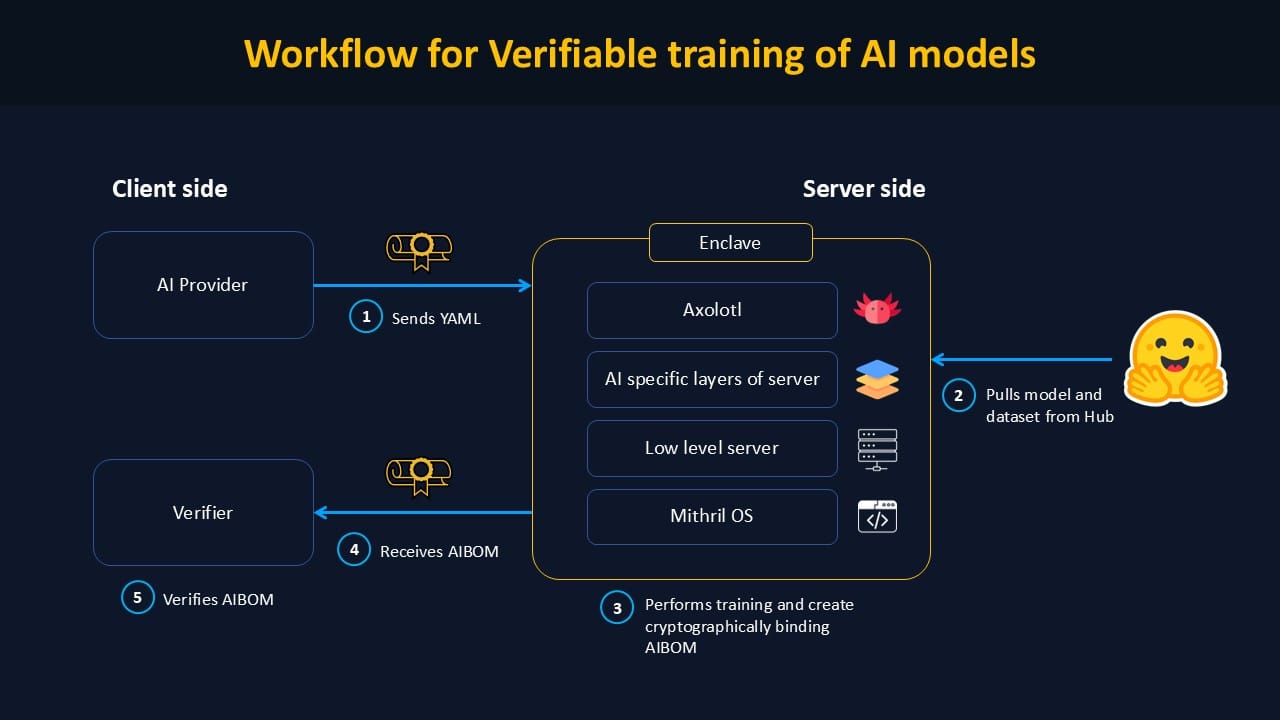
AICert works by transforming the model's training inputs—such as the procedure in an Axolotl configuration—into a model card that binds the output weights to hash values of inputs like code, compute usage. The resulting model card is certified by the TPM's tamper-proof Attestation Key, preventing falsification from a third party. With access to the training inputs, anyone can verify whether the cryptographic hashes match with the claimed data, transforming AI training from declarative to provable.
Currently, our proof-of-concept focuses on fine-tuning, but we aim to expand it to the full training process.
What is the root of trust?
The system is built upon Trusted Platform Modules (TPMs), cryptographic modules that underpin AICert’s integrity. TPMs first verify that system components haven’t been tampered with. They then bind the inputs and outputs of the fine-tuning process, providing cryptographic hash values for all key elements relating to the model’s provenance. This ensures that users can verify the entire software stack used during training, promoting trust and transparency in AI deployment.
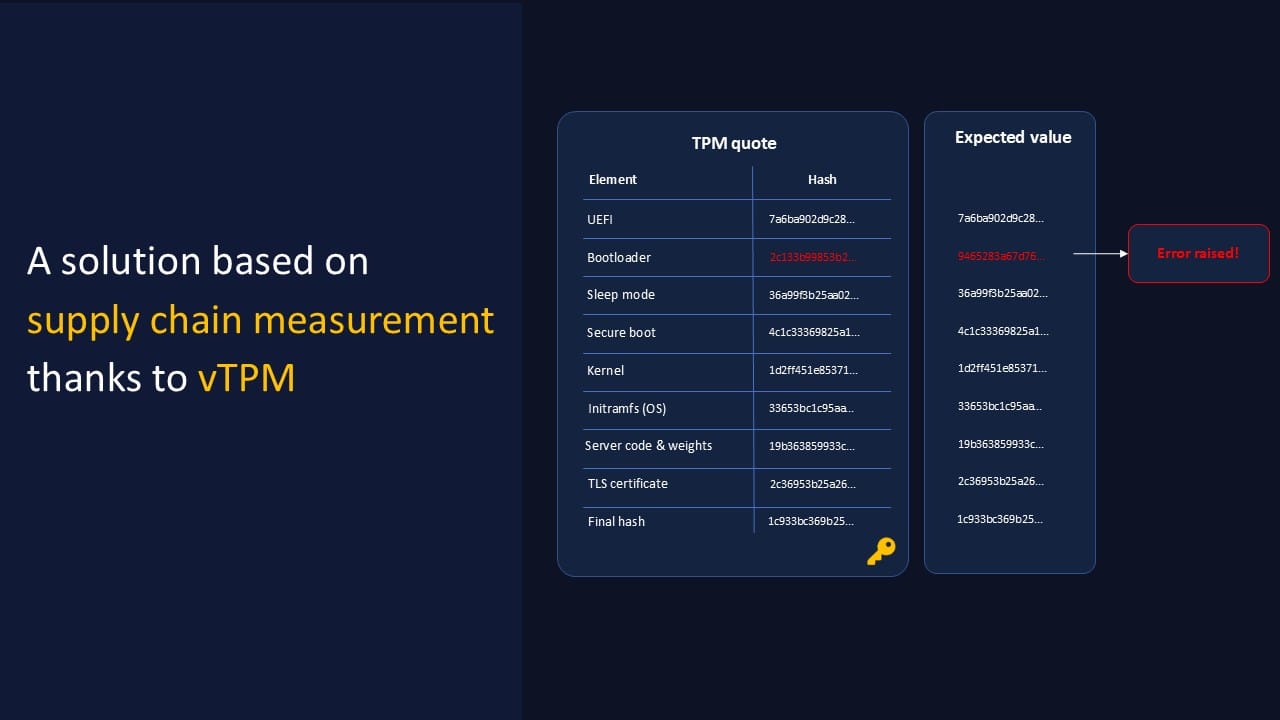
Looking forward, regulators could use a framework built on AICert to verify AI models' compliance with local regulations, ensuring users are protected from security risks.
How Can I Use AICert?
- Fully open product: AICert is available on GitHub.
- Check the doc: You can follow the guide in the documentation to get started. If you need help or additional information, don’t hesitate to reach out!

{kind=link}