
Confidential Computing Explained. Part 3: Data In Use Protection
Deep dive into the data-in-use protection mechanisms of secure enclaves
Confidential computing explained:
Part 3: data in use protection
I - Introduction
We saw in the previous articles how Confidential Computing could help data owners share their data with third parties for analysis, without fearing data leaks.
This is possible thanks to the use of secure enclaves, hardware-protected environments where sensitive data is manipulated by third parties, with guarantees of end-to-end protection, including the people who operate the enclave.
There are two properties that Confidential Computing provides to make this possible:
- Data in use protection: data manipulated in secure enclaves are not accessible to outside operators. This implies that you can share sensitive data to third parties as you no longer need to trust them with your data, as they have no way to compromise it.
- Remote attestation: the code and security properties of enclaves can be verified remotely. This implies that you can make sure you are talking to a genuine enclave, with the right code and security patch, before sending your data. This provides transparency and traceability because you will know exactly what will be done to your data, and you can have cryptographic hardware-backed proofs that only a code you know and trust was used.
In this article we will focus on the first property, data in use protection with secure enclaves, with a focus on Intel SGX, to see how the hardware can protect the content of enclaves.
II - Current thread model and issues
To understand the improvements provided by secure enclaves, it is good to first remind ourselves of the current state of trust.
A - Data Exposure
Let's take an example. Imagine you have a hospital that wants to resort to an AI-aided diagnosis tool. Because it is not necessarily their job to manage complex infrastructure and algorithms, they want to resort to an external AI startup which will provide it to them.
For ease of deployment, and as a natural option for startups, this startup provides its solution with a simple API where you can send your medical data to be analyzed. But this is where problems begin.
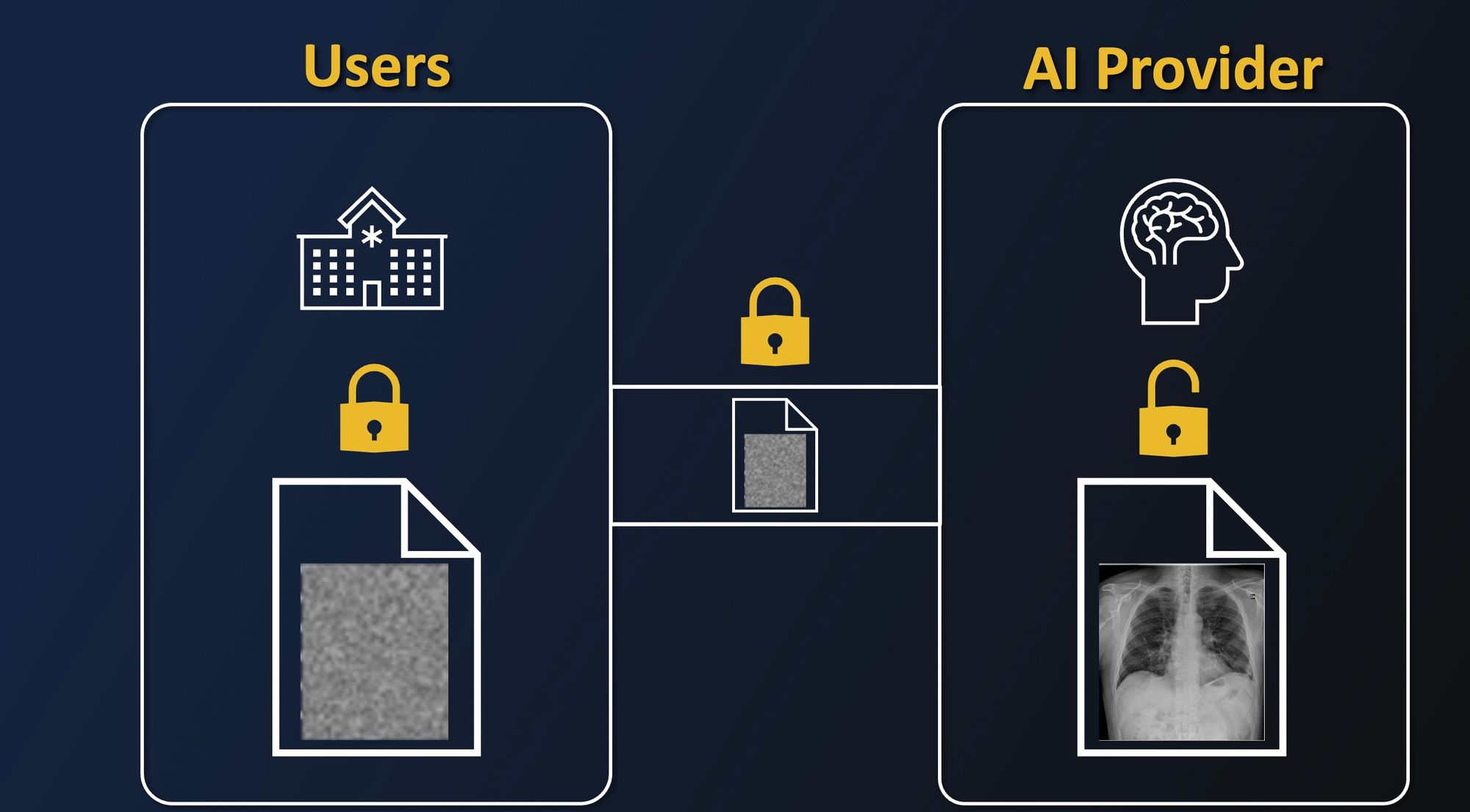
As we mentioned before, most solutions today only provide protection in storage and in transit. This means that as soon as you need a third party to analyze your data, enrich it, apply an algorithm on it, cross it, etc. they will need to have access to it in clear.
This implies that you have to trust them with your data, as now if the company is malicious, has a rogue admin, or is compromised, your data is exposed to uncontrolled usage.
Securing this last piece, analysis by third parties is crucial to unlocking scenarios where we want strong security and privacy guarantees when sharing data with third parties, for instance, to train or deploy an AI model.
End-to-end protection, including during analysis, will alleviate those concerns, as data is no longer exposed to anyone else in clear, and therefore its exposure risks are much more limited.
Without end-to-end protection, we currently have to trust the third parties handling our data. But what does it mean to trust others? What do we have to trust? Who do we have to trust?
B - The Trusted Computing Base
To answer this question, let us have a look at the Trusted Computing Base (TCB), which represents the different pieces of hardware and software you need to trust today.
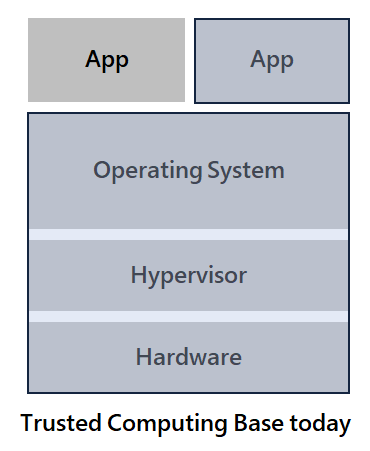
If we go back to our example with the startup with an AI diagnosis tool hosted in the Cloud, then you have to trust:
- The startup provides the software to handle your data and apply an AI algorithm to it.
- The Cloud provider manages the underlying infrastructure and can very easily get access to its tenants' data, for instance using privileged access from the OS or Hypervisor. We will see an example of dumping and reading users' data later in this article.
This means we need to trust a lot of people and things when sharing our data with third parties:
- The people involved must not be malicious, because once we send data to them, we have no way of making sure they are not selling or using our data without our knowledge.
- The pieces of code involved must not be compromised, as for instance, a vulnerability in the OS or Hypervisor could expose users' data.
Because of this, the current Trusted Computing Base is huge, and it becomes hard to provide technical privacy and security guarantees to data owners when they want to share data with external solutions.
But this is where Confidential Computing comes in, to reduce as much as possible the TCB and provide those technical guarantees so that data can be shared without fear of exposure!
III - Threat model shift with Confidential Computing
To see how secure enclaves with Confidential Computing help secure data processing, let's dig deeper into Intel Software Guard eXtension (SGX).
A - Data in use protection with secure enclaves
The idea is that most Intel CPUs with the SGX feature are able to create enclaves, which will be programmed in charge of handling sensitive data.
Data manipulated by enclaves will be protected, even from the service provider who will have provided the code and logic of the enclave, as the hardware will provide isolation and encryption of enclaves’ content:
- Enclave memory is in an isolated memory area.
- Enclave memory cannot be read or written from outside the enclave, regardless of the privilege level and CPU mode. An attempt to access enclave memory results in a page abort.
The memory of the enclave is encrypted at all times while it is in RAM (with AES) by a key that is only available to the CPU. The data is only decrypted while being processed by the CPU.
Therefore, dumping the RAM memory will only give access to encrypted data unusable by the attacker. This removes a whole class of difficult to tackle attacks such as cold boot attacks.
Thanks to all those properties, enclaves are well suited to manipulate sensitive data securely. If we go back to our previous example with the secure analysis of medical data, let's see how enclaves reduce data exposure.
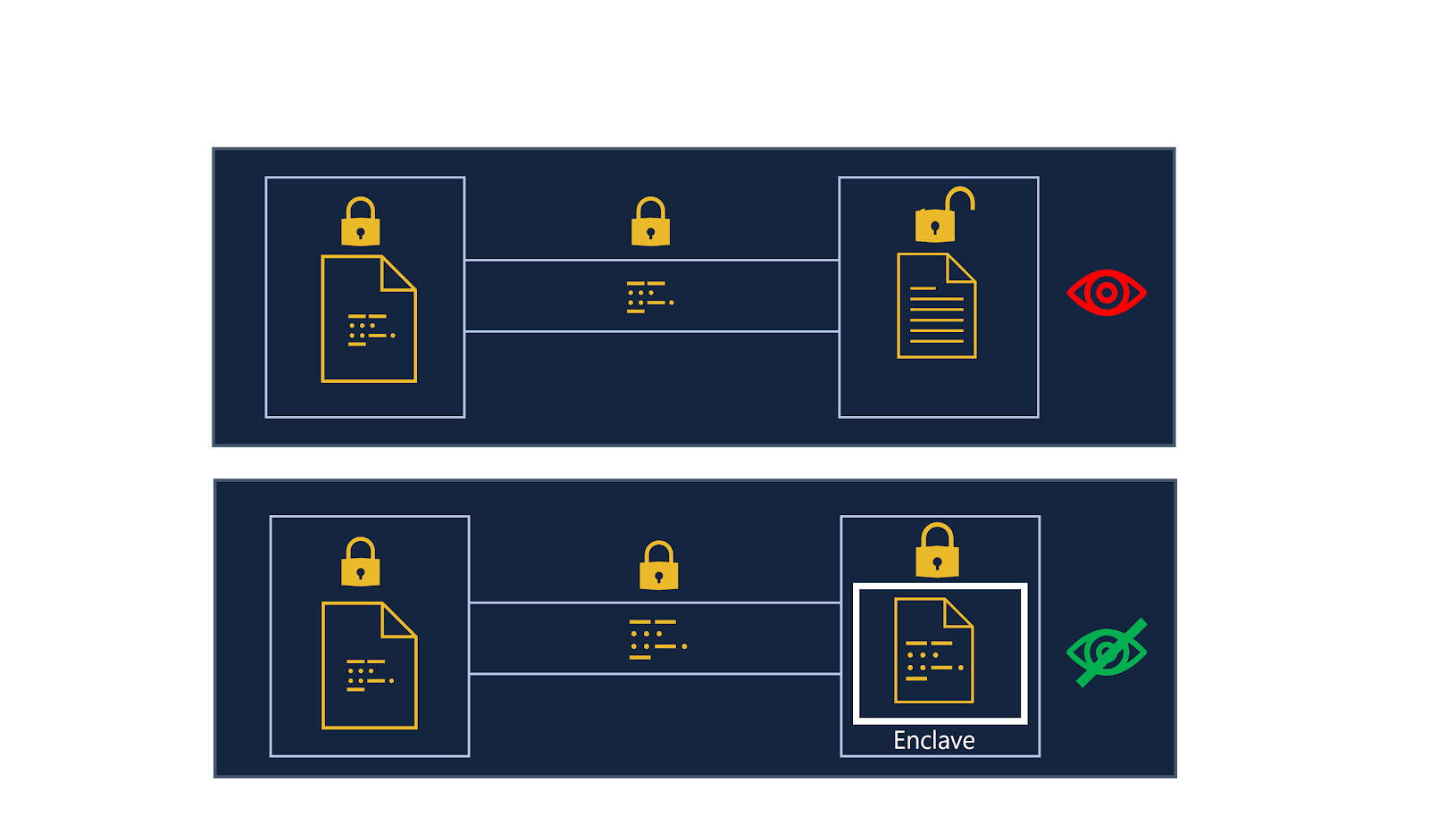
To make data end-to-end protected, the main idea is that data owners will send their data encrypted with a key only shared with the enclave.
While data is in clear inside the enclave, it is not accessible to the service provider thanks to memory encryption and isolation provided by the hardware.
Data will be processed by the enclave, then the result is encrypted and sent back to the user.
Thanks to this mechanism, we no longer expose data to service providers as the only time data was in clear was inside the enclave, but the hardware will protect it from the outside, therefore providing end-to-end protection.
B - Separation between enclave and host
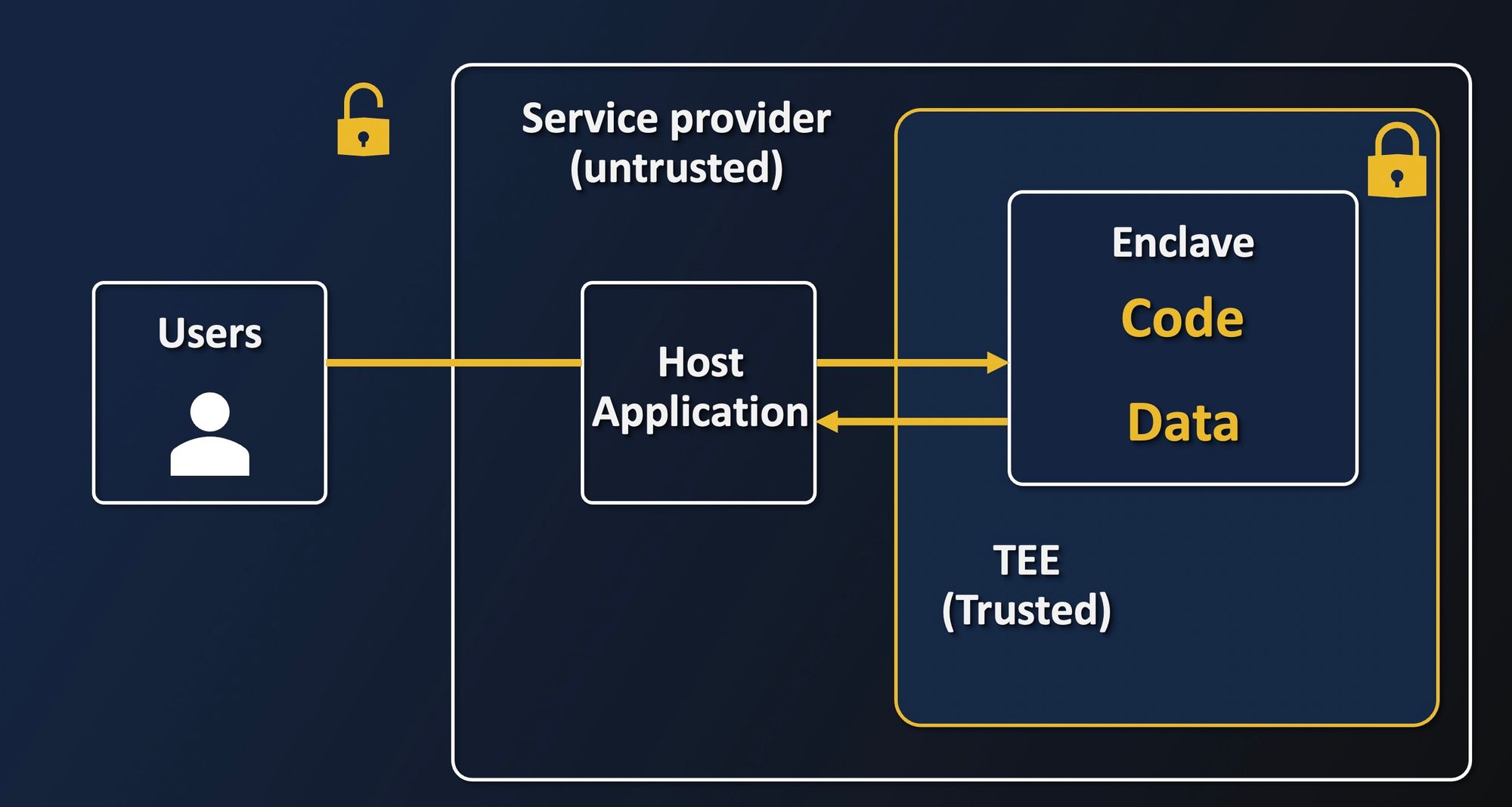
Now that we have seen how enclaves are protected, let us have a look at how enclaves are separated from the rest. The idea with Intel SGX is to put just the necessary amount of code inside the enclave to manipulate the sensitive data. In practice, we only provide the enclave with all the crypto tools to encrypt/decrypt data, prove the enclave's identity, and everything needed to process the data, for instance, numeric libraries for Deep learning, and nothing more.
All other tasks are delegated to the host, which includes the OS and Hypervisor, that are not trusted in this setup. Those will be in charge of forwarding the data to the enclave, which has no access to the filesystem or network. At no point should the host have access to the secrets directly. The host is untrusted here and only serves the enclave to the outside world.
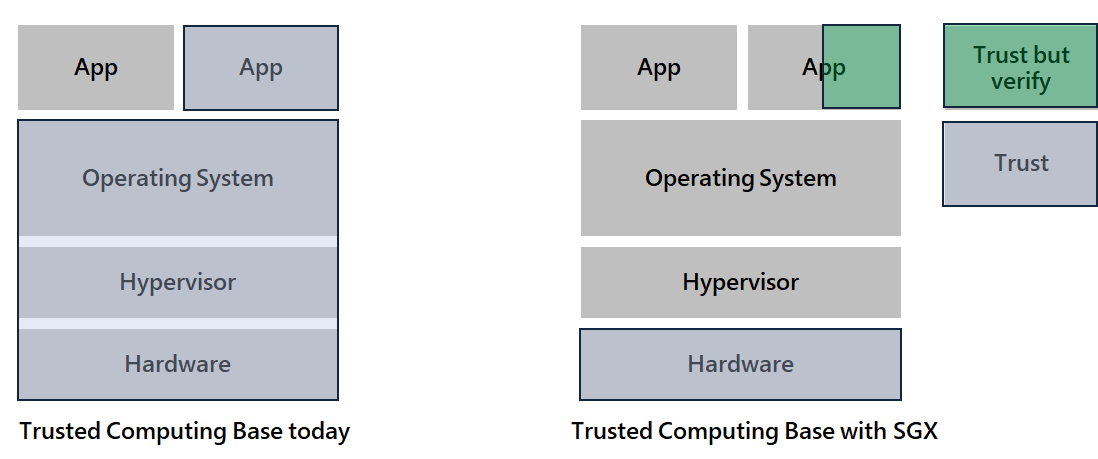
With this separation from Intel SGX, the TCB is greatly reduced. If we go back to the example of the remote AI diagnosis tool provided by a startup hosted in the Cloud:
- The OS and Hypervisor provided by the Cloud provider, are outside of the TCB, as we no longer need to trust them. This greatly reduces exposure to security vulnerabilities, and the need to trust the Cloud provider.
- The tenant, here the startup that provides the service, also has no way to know what data their clients will share with their enclave thanks to the hardware protection.
Here we mention "Trust but verify" for the enclave application code, because even though the contents of the data are protected from the outside if a malicious enclave is provided, data can be leaked. Trust is achieved by auditing the enclave code which should be opened for review.
Conclusion
We have seen throughout this article that Confidential Computing greatly reduces the Trusted Computing Base, with a minimal attack surface. It provides data-in-use protection through hardware isolation of enclaves' content, therefore enabling a third party to process data without being able to access their data.
In the next article, we will see how with a simple code example, it means in practice to extract data from an unprotected environment, and how enclaves can secure data in use.


{kind=link}