
Large Language Models and Privacy. How Can Privacy Accelerate the Adoption of Big Models?
We will see why security and privacy might facilitate the adoption of Large Language Models, as those vast models push towards centralisation, given the complexity of deploying them at scale.
We will see why security and privacy might facilitate the adoption of Large Language Models, as those vast models push towards centralization, given the complexity of deploying them at scale.
This post is part of the series on Large Language Models and privacy.
Part 1: how can privacy accelerate the adoption of big models
Part 2: deploy a GPT2 model with privacy using BlindAI
Introduction
Large Language Models have recently amazed the general public with the expressive power of AI and ultimately changed the deep learning ecosystem.
Like GPT3 and OpenAI Codex, powering GitHub Copilot, such models have shown impressive performance in solving a simple yet challenging task: finishing a text prompt given by a user.
Those so-called "Foundation Models" hold great promise as they help answer many use cases, from translating one language to another to helping write journalistic articles through code or documentation suggestions.
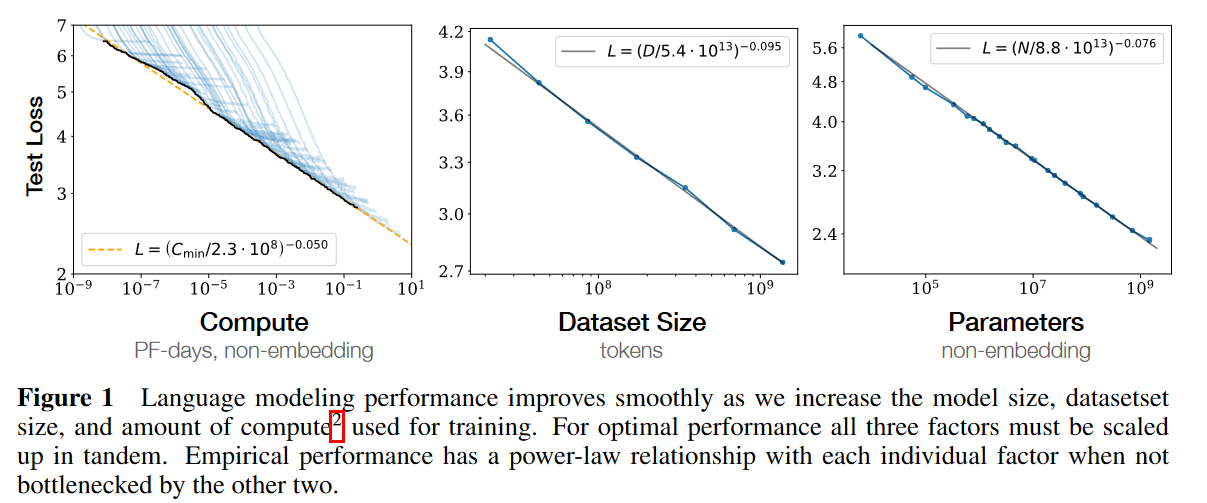
The paper Scaling Laws for Neural Language Models highlights an exciting trend. There seems to be a power law governing those models, where performance depends on scale (number of parameters, dataset size, and compute). This would point towards having bigger models to get better results.
However, those Large Language Models can meet two obstacles to their global adoption: infrastructure and IP protection.
Regarding the infrastructure, the need for state-of-the-art hardware, software, and engineers to make those models work can be a great show-stopper for on-premise deployment.
Indeed, let's consider, for instance, use cases in healthcare. It is hard to imagine that hospitals would have enough time and money to invest in the infrastructure needed to deploy a GPT3-based model to help analyse medical documents.
Regarding IP protection, deploying those models on-premises comes with the risk of reverse engineering. Those models are costly to train, so weights represent a high-value IP asset.
Those reasons explain the growing trend to provide Large Language Models through Cloud-based API:
- Infrastructure requirements: hosting the model in specialised data centres, e.g. in the Cloud, removes the need for complex infrastructure. It becomes pretty easy to feed data to these models and get a result.
- IP protection: it becomes much more challenging for AI consumers to steal the model's weights (notwithstanding model extraction attacks with a black-box API).
Additionally, given the power requirements of those models, it also makes sense from an ecological perspective to rely on specialised data centres rather than on-premise deployment.
The economies of scale that Cloud Providers leverage make them more energy efficient than companies deploying on-premise.
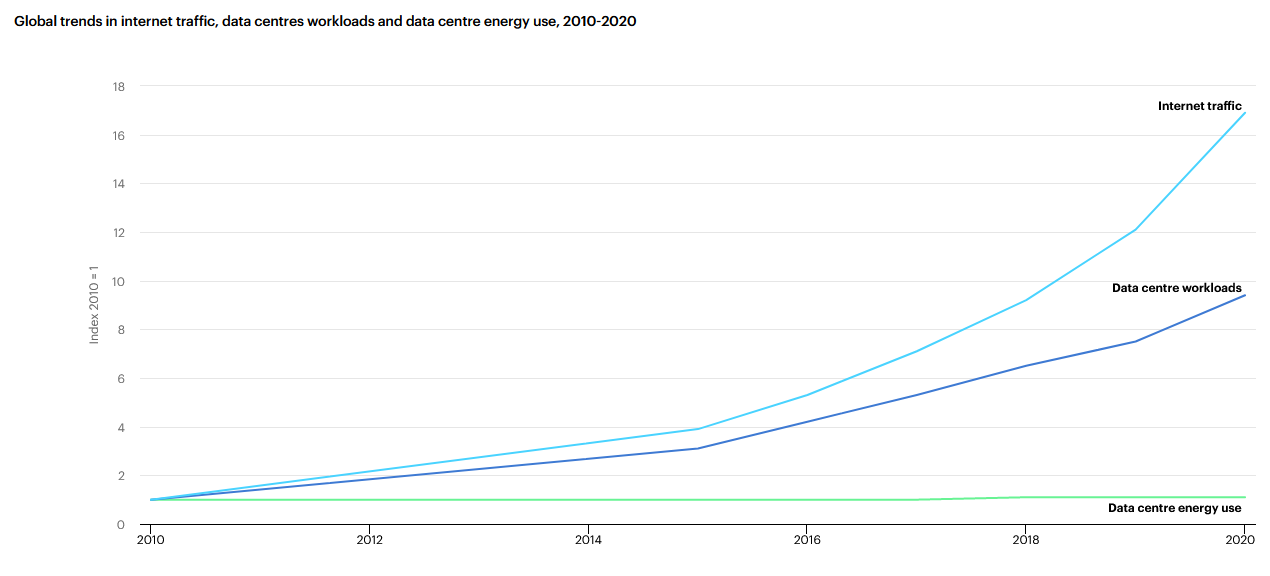
Indeed, data centres have become increasingly more energy efficient, as the above graph shows. While global internet traffic and data-centres workload has increased, data centre energy consumption has remained constant.
In addition, Cloud Providers can choose to set up their data centres where electric power is produced thanks to renewable energy sources. For instance, Quebec has 94% renewable energy from its hydroelectric complex, making it a place of choice to host a sustainable data centre.
Nonetheless, this centralisation has a downside. From security and privacy perspectives, Cloud hosting comes at a cost. It exposes data to new risks: sensitive data becomes potentially exposed to the actors providing those large models and the Cloud Provider.
If one actor (either the Cloud or the solution provider ) is compromised or malicious, thousands of users' data can be exposed.
While centralisation could help answer scalability, IP protection, and energy consumption, we still need to answer the privacy and security issues linked to trusting sensitive data to centralised actors.
Fortunately, Privacy Enhancing Technologies aim to solve these challenges resulting from Cloud hosting. We will see how we can leverage them to deploy Large Language models through an example with BlindAI, an Open-Source Confidential AI deployment project.
Introducing Privacy-Enhancing Technologies
Today, most AI tools offer no privacy by design mechanisms, so when data is sent to be analysed by third parties, the data is exposed to malicious usage or potential leakage.
We illustrate it below with the use of AI for voice assistants. In addition, those kinds of audio recordings are often sent to the Cloud for analysis without users' knowledge or consent, exposing conversations to leaks and uncontrolled usage.
Even though data can be sent securely with TLS (transfer), some stakeholders in the loop can see and expose data while it is accessible in RAM for analysis (in use), such as the AI company renting the machine, the Cloud provider or a malicious insider.
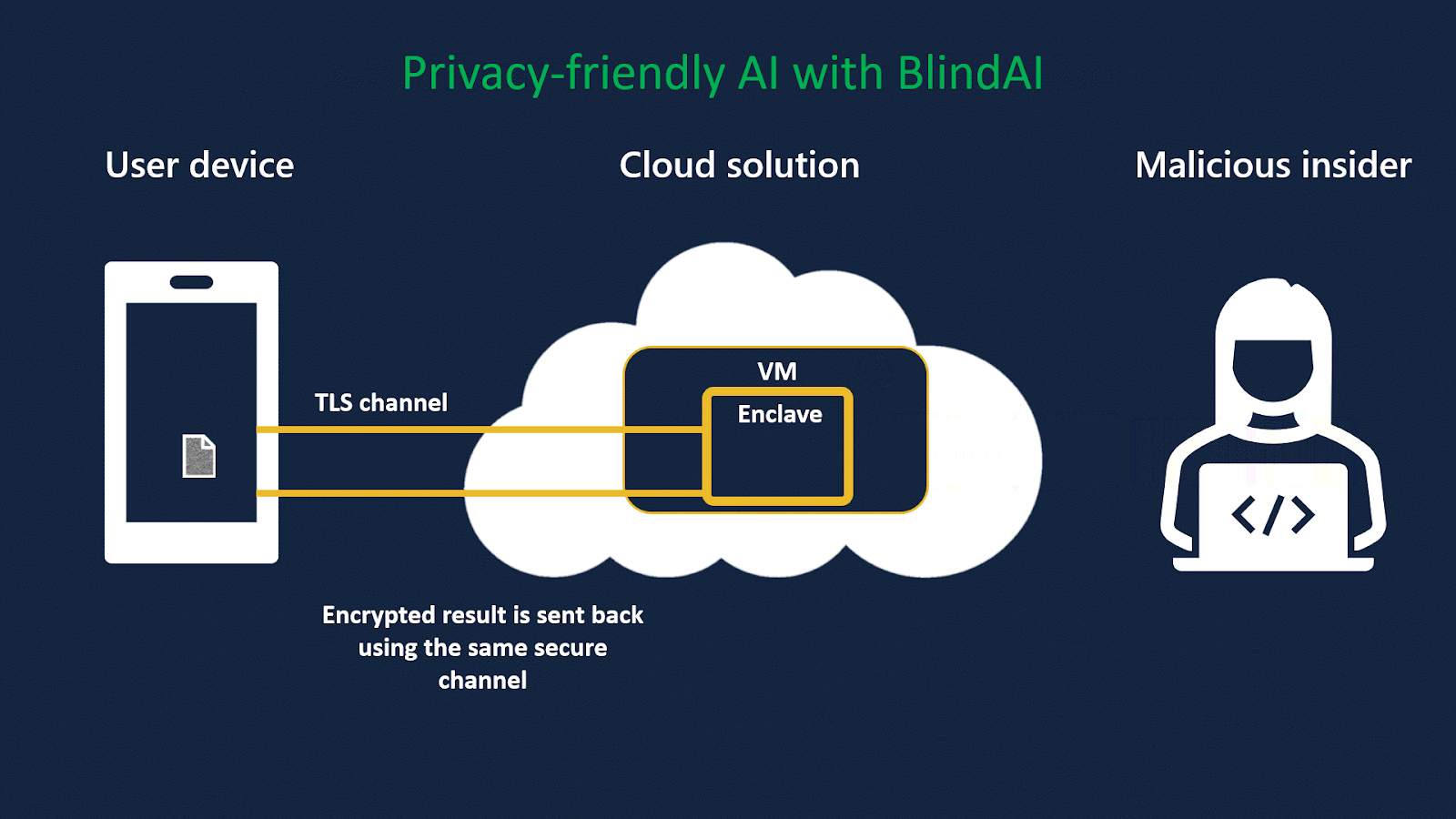
Privacy Enhancing Technologies, like homomorphic encryption, secure multi-party computing or secure enclaves, have emerged to answer that challenge. They provide ways to analyse other people's data while keeping it encrypted so that users can now share their data with third parties without worrying about privacy.
At Mithril Security, we focus on secure enclaves as this technology currently provides the best tradeoff between speed, security and ease of deployment.
BlindAI is our open-source AI deployment solution using secure enclaves. With BlindAI, data remains always protected as it is only decrypted inside a Trusted Execution Environment, called an enclave, whose contents are protected by hardware. While data is clear inside the enclave, it is inaccessible to the outside, thanks to isolation and memory encryption. This way, data can be processed, enriched, and analysed by AI without exposing it to external parties.
Hence, by providing data protection even when data is sent to an untrusted party, we facilitate the adoption of AI in the Cloud.
You can find out more about Confidential Computing in our series Confidential Computing Explained or our tutorial.
In the following article, we will show you how you can use BlindAI to deploy a GPT2 model inside an enclave.
Conclusion
We have seen in this article how promising Large Language Models are, but also why their deployment can pose challenges. Cloud computing is a natural way to facilitate its diffusion, but security and privacy become new challenges.
Fortunately, Privacy Enhancing Technology such as secure enclaves enables us to reconcile the best of both worlds. We will see a concrete example in the following article with BlindAI and GPT.
We hope you liked this article! If you are interested in privacy and AI, do not hesitate to drop a star on our GitHub and chat with us on our Discord!


{kind=link}